Build Custom Connectors with Connector SDK
Fivetran’s Connector SDK allows you to develop a custom data connector using Python and deploy it as an extension of Fivetran. Fivetran automatically manages running Connector SDK connections on your scheduled frequency and manages the required compute resources, eliminating the need for a third-party provider.
Connector SDK provides native support for many Fivetran features and relies on existing Fivetran technology. It also eliminates timeout and data size limitations seen in AWS Lambda.
Custom connector development process
When developing a custom connector using the Connector SDK, given that all prerequisites are in place, the high-level end state workflow is as follows:
- Install the Connector SDK.
- Write code to extract data from your source and pass to the Fivetran Connector SDK.
- Test your code locally.
- Deploy the code to Fivetran to create your connection.
- When running a sync, Fivetran runs your custom code so that it can extract data from your source and send it to Fivetran.
- Fivetran then loads the data into your destination.
Follow our Connector SDK setup guide for custom connectors and visit our Connector SDK GitHub Repo to create a custom source connector and connect it with your destination using Fivetran.
Alternatively, follow our Connector SDK Beginner's Tutorial for an end-to-end beginner-friendly tutorial.
Connector development best practices
To help you build a custom connector, we've prepared a list of best practices for you to follow:
- Optimizing performance when handling large datasets
- Using state incremental sync best practices
- Consider centralizing deployment to a code deployment system
- Declare columns and data types only as necessary
- Declare primary keys
- Upgrade your Fivetran Connector SDK
- Use a revision control system
Key features of the Connector SDK
| Feature Name | Supported | Notes |
|---|---|---|
| Capture deletes | ||
| History mode | ||
| Custom data | ||
| Data blocking | ||
| Column hashing | ||
| Re-sync | ||
| Row filtering | ||
| API configurable | API configuration | |
| Priority-first sync | ||
| Fivetran data models | ||
| Private networking |
| |
| Authorization via API |
The Connector SDK does not support History Mode. However, you can mimic its behavior by including a timestamp column as part of a composite primary key.
The Connector SDK supports many Fivetran features natively, as if the connector was developed by Fivetran, including:
- Column blocking
- Column hashing
- Data de-deduplication
- Destination ingestion optimizations
- Any connection method supported by Python libraries that you can include in your Python
requirements.txtorpyproject.tomlfile
The following features are available for implementation in your custom code, but only if the source allows it:
- Incremental updates
- Updating and upserting data operations and soft deletion of data. We only support these operations for the records with defined primary keys.
- Table-level re-sync. You must implement this functionality in your custom code.
- Multi-threading for fast extraction of data from the source
- Customizing the data schema delivered to your destination
- Defining data types in the schema used to deliver data to your destination
- Source data type inference. This applies only if you are not defining the data type to be used for a column in your code.
- Automatic schema updates. See our changing data type documentation for more information.
- Controlling the state and connection-level re-syncs of the connection
- Authenticating with OAuth 2.0 Client Credentials flow
Supported deployment models
We support the SaaS and Hybrid deployment models for the connector.
You must have an Enterprise or Business Critical plan to use the Hybrid Deployment model.
The following diagram outlines the architecture of the Hybrid Deployment model for Connector SDK:
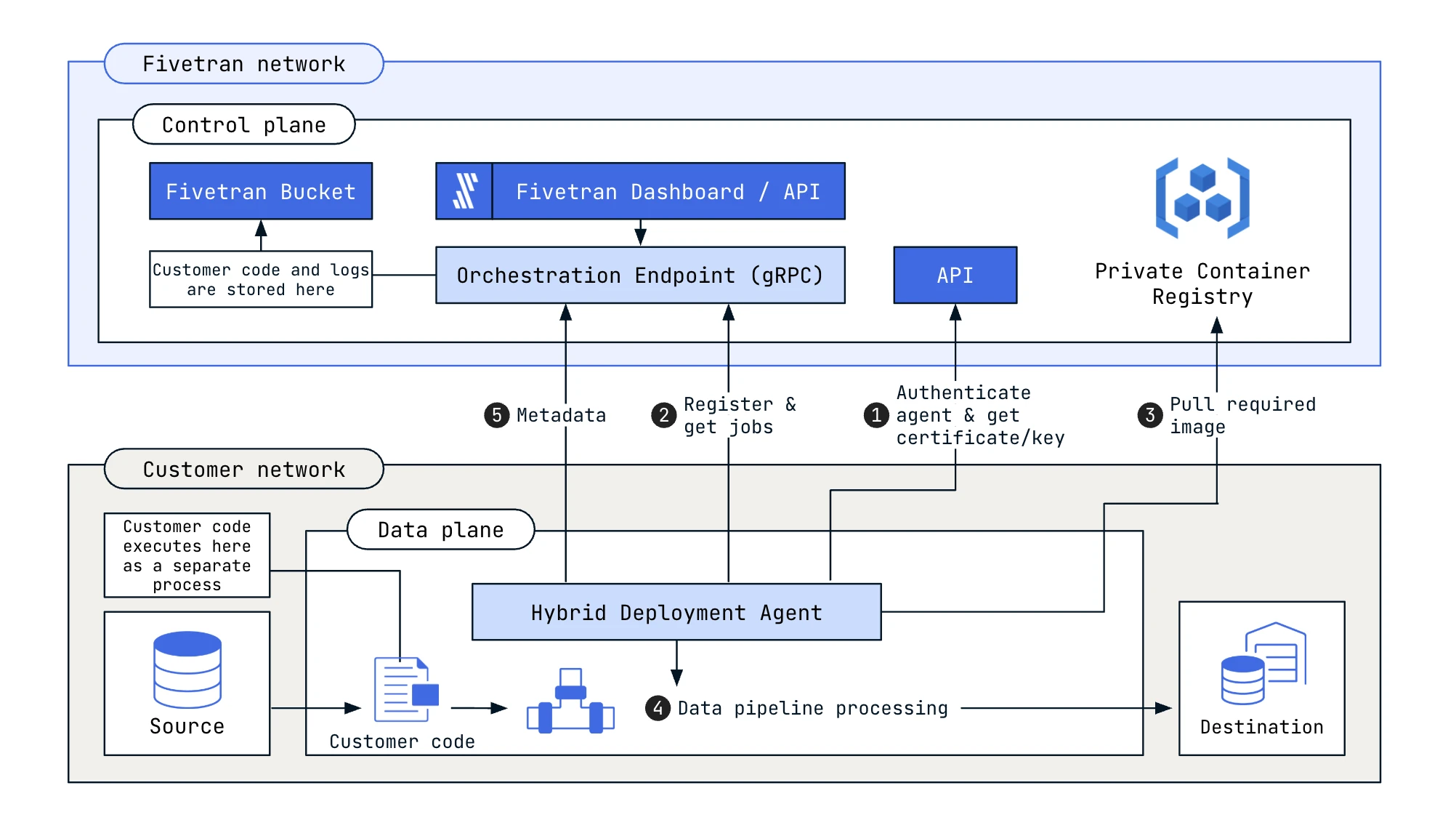
See our Connection Options documentation to learn more about the connection options we support.
Use cases for custom connectors
The Connector SDK service is a good fit for the following use cases:
- Fivetran doesn't have a connector for your source or is unlikely to support it in the near future.
- You are using private APIs, custom applications, unsupported file formats or those that require pre-processing.
- You have sensitive data that needs filtering or anonymizing before entering the destination.
- You don't want to introduce a third party into your data pipeline (for example, to host a custom function).
Connector SDK architecture
The following diagram provides a high-level overview of how connectors built using the Fivetran Connector SDK work:
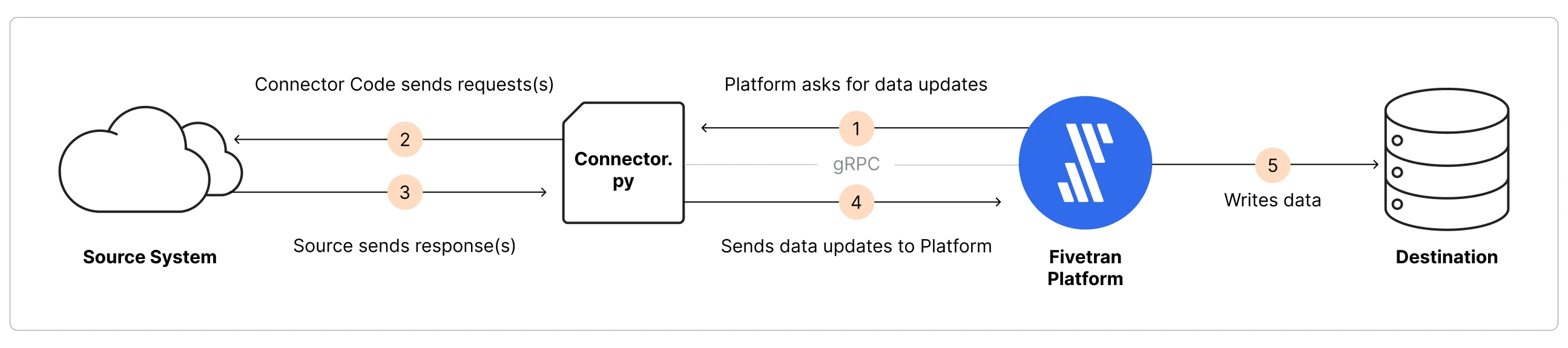
The Connector SDK runtime environment executes your custom Python code in an isolated, secure environment. When a sync is triggered, the runtime environment installs the Python libraries listed in the requirements.txt or pyproject.toml file and then runs your connector.py script.
By default, we host and run your Connector SDK connection in GCP, Fivetran's default infrastructure provider, in the region that you have configured in your destination. If you are on our Enterprise or Business Critical plan, you have the option to choose a cloud service provider and cloud region. In that case, we will host and run your code in the cloud provider and region you selected for the rest of your Fivetran infrastructure.
To support various connectivity scenarios, the runtime environment comes with several pre-installed drivers and packages. For more details about the runtime environment, Python version support, system resources, and other technical specifications, see our SDK runtime environment documentation.
See the SQL Server example to learn how to use these pre-installed drivers in your connector code.
Secret management
We store configuration values securely, and we encrypt them the same way as credentials for other connections. Learn more in our Data and Credential Encryption documentation. To pass configuration values for use in your code, you can upload them using the configuration.json file when you deploy your connector, or you can define an optional setup form so users can enter values in the dashboard. We don't store configuration.json with your code, and we recommend that you delete it from your local project after you deploy the connector. We read the values, encrypt them, and store them securely. The values are only available to your code at runtime. You can confidently use configuration values to pass any credentials required to run your connection, like a key required to make an API call.
Support for hosted Python environments
You can use a hosted Python environment, such as Jupyter Notebook, to test Python libraries and approaches to validate how you are going to connect to your data source and manipulate the response data ready for sending to Fivetran.
However, you need to send the actual connector.py file to Fivetran because we execute it in our infrastructure each time a sync is triggered. As such, it needs to be a standalone Python script or a set of scripts that are called from your connector.py file.
See Technical Reference for a list of supported methods, operations, and fivetran-connector-sdk commands.
Connector SDK vs. Fivetran alternatives
Besides Connector SDK, we offer native connectors and development programs that cover a wide range of ELT use cases. For a better understanding of what best fits your needs, see the sections below.
Connector SDK vs. Lite connectors
Lite connectors are API-based connectors that Fivetran builds through our By Request program for SaaS applications that produce a non-dynamic schema. They are built quickly for specific use cases and often cover fewer endpoints than standard connectors.
In contrast, Connector SDK enables you to build your own custom connector for your custom data source. You write and maintain the connector code in Python, and deploy them to run either on your cloud service infrastructure or on Fivetran's infrastructure.
The following table summarizes the key differences between connectors built in our By Request program and using Connector SDK:
| Aspect | By Request (Lite) | Connector SDK |
|---|---|---|
| Use cases | Complete or near-complete use case coverage | Customer-decided use case. Custom solution hosted by Fivetran |
| Release cycle | Private Preview, then Generally Available. No Beta phase | Live upon deployment. Setup can be fully automated |
| SLA | Full SLA based on pricing plan | Customer-driven SLAs |
| Hosting or requirement for the 3rd party to run the code you write. | Fivetran | Fivetran |
| Supported Language | Not applicable since Fivetran writes the code | Python |
Connector SDK AI plugins vs. AI Connector Agent
Connector SDK AI plugins are AI-assisted tools that integrate with coding agents such as Claude Code, Codex CLI, GitHub Copilot CLI, and Gemini CLI to help you build, test, and deploy Connector SDK connectors. You still write and maintain the connector code in Python. The plugins accelerate the development workflow.
Use Connector SDK AI plugins to build custom connectors for any data source, such as a database or a private REST API, or to customize any of our 700+ native connectors.
The AI Connector agent is a web app that generates production-ready connectors for SaaS sources automatically from the source's REST API documentation. No code is required; you provide the source's API documentation, configure authentication, and Fivetran handles deployment and infrastructure.
Use an AI connector agent when your source is a SaaS application with a publicly documented REST API, and you want Fivetran to fully manage the connector without writing or maintaining any code.
Limitations
The Connector SDK doesn't support the following features:
- Webhooks for receiving event data
- History Mode
- Table-level re-syncs from the Fivetran dashboard
- Pre-built Fivetran data models
To create a Connector SDK connection via REST API, you must first create a package using the Connector SDK Package Management API, then use the standard Create a Connection endpoint with the returned package_id in the config. Alternatively, use the fivetran deploy CLI command which handles both steps automatically.
You can manage Connector SDK connections using all endpoints available in the Connection resource. Learn how to manage your Connector SDK connection using the Fivetran REST API in our Managing a Connection using the Fivetran REST API Tutorial.
Support and resources for connector development
Our Support Team triages all tickets submitted though the Support Portal:
- If the issue is with the Fivetran platform, our Support Team will work with you on the issue until it is resolved.
- If the issue is with the connection’s custom code or logic, our Professional Services Team can assist you.
The scope of our Customer Support Team's assistance is limited when it comes to troubleshooting custom code issues.
If you need assistance in developing a custom Connector SDK connector, our Services team can help. Contact your Account Representative to use existing service hours you may already have or submit a support request to get started with our Services team.
Connector SDK Maintenance
Connector SDK Maintenance is an optional add-on for customers who want Fivetran to manage the ongoing health of their existing SDK-built connectors. This is a maintenance service — it doesn't include building new connectors.
When you purchase Connector SDK Maintenance, Fivetran will:
- Review your code at a high level to confirm it follows error handling and logging best practices for the Connector SDK.
- Monitor your specified Connector SDK connections for severe log events and sync failures.
- Update your Python code if errors result from source changes. If a source introduces breaking changes, the Fivetran team will adjust the code and redeploy on your behalf.
This service doesn't include:
- Building new connections.
- Adding new functionality, such as support for new endpoints or tables, to a monitored connection.
- Performance improvements.
Shared responsibility model
Connector SDK Maintenance requires your ongoing partnership. You are responsible for:
- Validating your data.
- Notifying Fivetran of any known or upcoming changes to your source.
- Providing appropriate access to your environments.
- Redeploying or writing any Python code as needed.
To get started with Connector SDK Maintenance, contact your Account Representative.
Building custom Connector SDK connectors with AI
The Fivetran Connector SDK pairs well with AI coding copilots and we encourage you to try building a custom connector with your preferred copilot. Whether you're using tools like GitHub Copilot, Claude, CodeWhisperer, Cursor, Windsurf, Trae, or a custom in-house solution, AI can help accelerate your connector development workflow.
For example, we built a fully functioning custom Fivetran connector in about an hour using Anthropic’s Claude. Read our blog post, Building a Fivetran connector in less than an hour with Anthropic’s Claude AI, to learn more.
To support you in leveraging AI assistants with Connector SDK, we’ve created an AI Tutorials section in our Connector SDK GitHub repo. There you’ll find example prompts, quick-start guides, and a growing number of best practices for using AI copilots effectively when building custom connectors.
Additional connector development resources
See the links below for additional resources on Connector SDK connector development:
- Visit our Connector SDK GitHub repo for more details.
- Download the fivetran-connector-sdk PyPI package to set up Connector SDK on your local machine.
- If you're new to Python and running CLI commands, see our Connector SDK Beginner's Tutorial for step-by-step instructions.
- Follow our ready-to-deploy examples to deploy a connection quickly.
- Develop with AI and Connector SDK.
- Learn how to build a Fivetran connector in less than an hour with Connector SDK and Anthropic’s Claude AI.
- See our video tutorial to learn how to build a Fivetran connector with Cursor AI.
- Try our fivetran-api-playground to explore various sample API endpoints on your local machine, helping you better understand the complexities of real-world APIs.
- For more helpful tutorials, see our Connector SDK Tutorials section.
- For any issues with the development process, see our Connector SDK Troubleshooting documentation.
Usage and pricing
Connector SDK is available on all pricing plans. It uses Monthly Active Rows (MAR) to calculate usage, just like any other Fivetran connector.
To calculate the MAR for a table in your Connector SDK, see How to Count Daily MAR Usage per Table.