Databricks Setup Guide
Follow our setup guide to connect Databricks to Fivetran.
If you used Databricks Partner Connect to set up your Fivetran account, you don't need to follow the setup guide instructions because you already have a connection to Databricks. We strongly recommend using Databricks Partner Connect to set up your destination. Learn how in Databricks' Fivetran Partner Connect documentation. To connect your Databricks workspace to Fivetran using Partner Connect, make sure you meet Databricks' requirements.
Supported cloud platforms
You can set up your Databricks destination on the following cloud platforms:
Prerequisites
To connect Databricks to Fivetran, you need the following:
- a Databricks account with the Premium plan or above
- a Fivetran account with permission to add destinations
- Unity Catalog enabled on your Databricks Workspace. Unity Catalog is a unified governance solution for all data and AI assets including files, tables, machine learning models, and dashboards in your lakehouse on any cloud. We strongly recommend using Fivetran with Unity Catalog as it simplifies access control and sharing of tables created by Fivetran. Legacy deployments can continue to use Databricks without Unity Catalog.
- SQL warehouses. SQL warehouses are optimized for data ingestion and analytics workloads, start and shut down rapidly and are automatically upgraded with the latest enhancements by Databricks. Legacy deployments can continue to use Databricks clusters with Databricks Runtime v7.0+.
Databricks on AWS - Setup instructions
Learn how to set up your Databricks on AWS destination.
Expand for instructions
Choose your deployment model
Before setting up your destination, decide which deployment model best suits your organization's requirements. This destination supports both SaaS and Hybrid deployment models, offering flexibility to meet diverse compliance and data governance needs.
See our Deployment Models documentation to understand the use cases of each model and choose the model that aligns with your security and operational requirements.
You must have an Enterprise or Business Critical plan to use the Hybrid Deployment model.
Choose a catalog
If you don't use Unity Catalog, skip ahead to the Connect SQL warehouse step. Fivetran will create schemas in the default catalog,
hive_metastore.
If you use Unity Catalog, you need to decide which catalog to use with Fivetran. For example, you could create a catalog called fivetran and organize tables from different connections in it in separate schemas, like fivetran.salesforce or fivetran.mixpanel. If you need to set up Unity Catalog, follow Databricks' Get started using Unity Catalog guide.
Log in to your Databricks workspace.
Click Catalog in the Databricks console and select your catalog.
You must set up Unity Catalog to sync unstructured files in Databricks. Without it, you won't be able to sync unstructured files.
Connect SQL warehouse
In the Databricks console, click + New > More > SQL warehouse. If you want to select an existing SQL warehouse, skip to step 6 in this section.
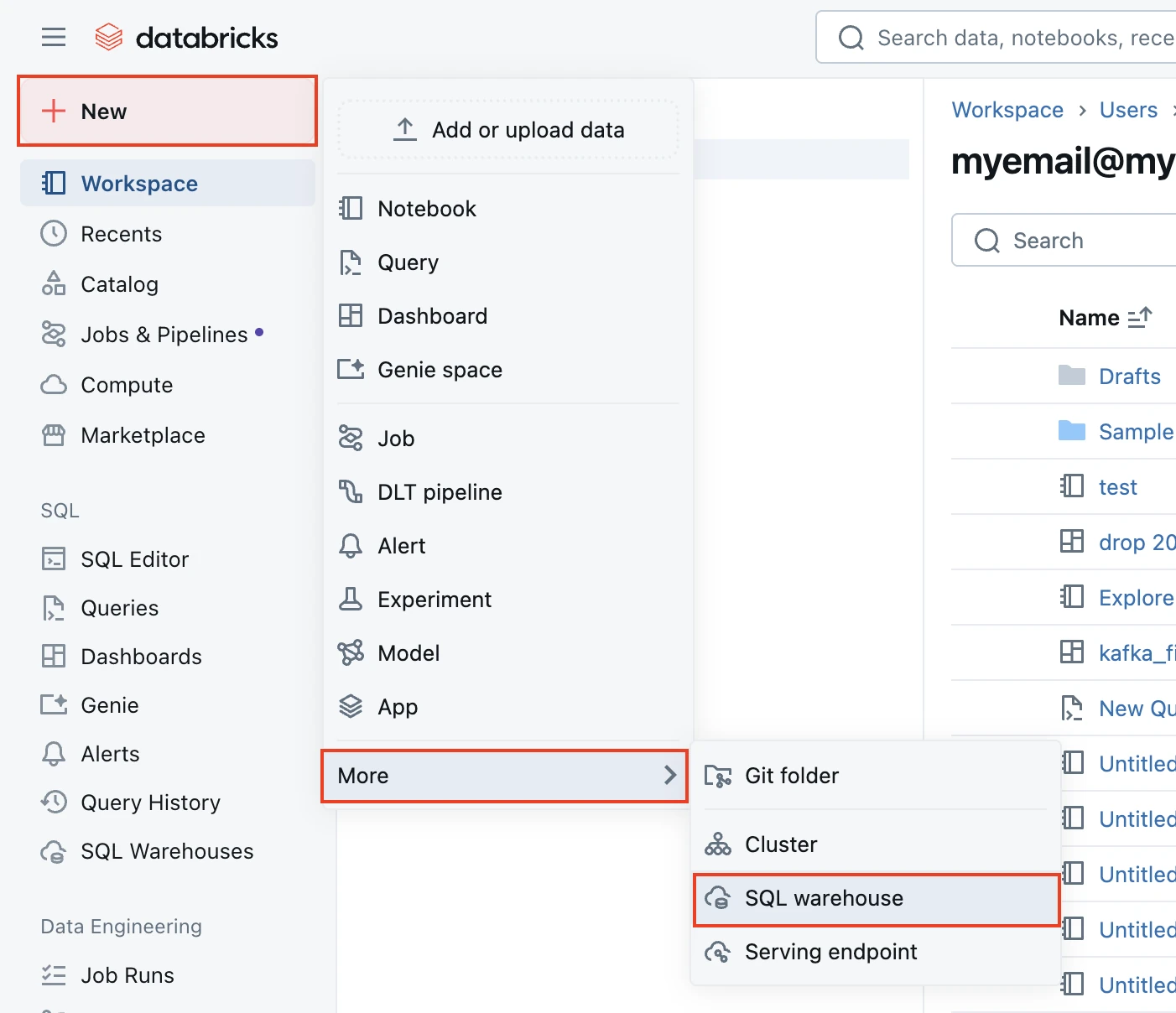
In the New SQL warehouse window, enter a Name for your warehouse.
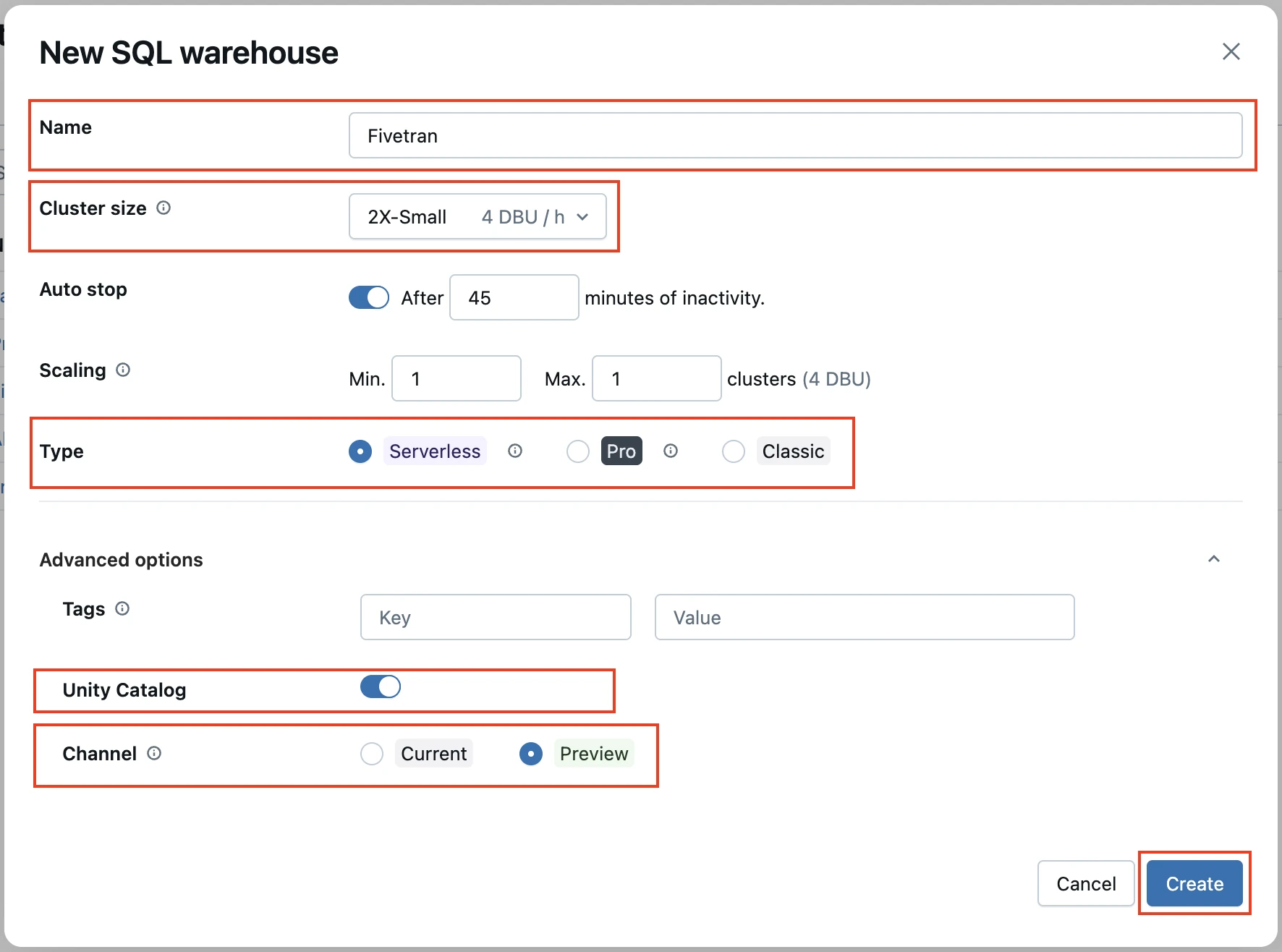
Select your Cluster Size and other warehouse options.
Click Create.
Go to the Connection details tab.
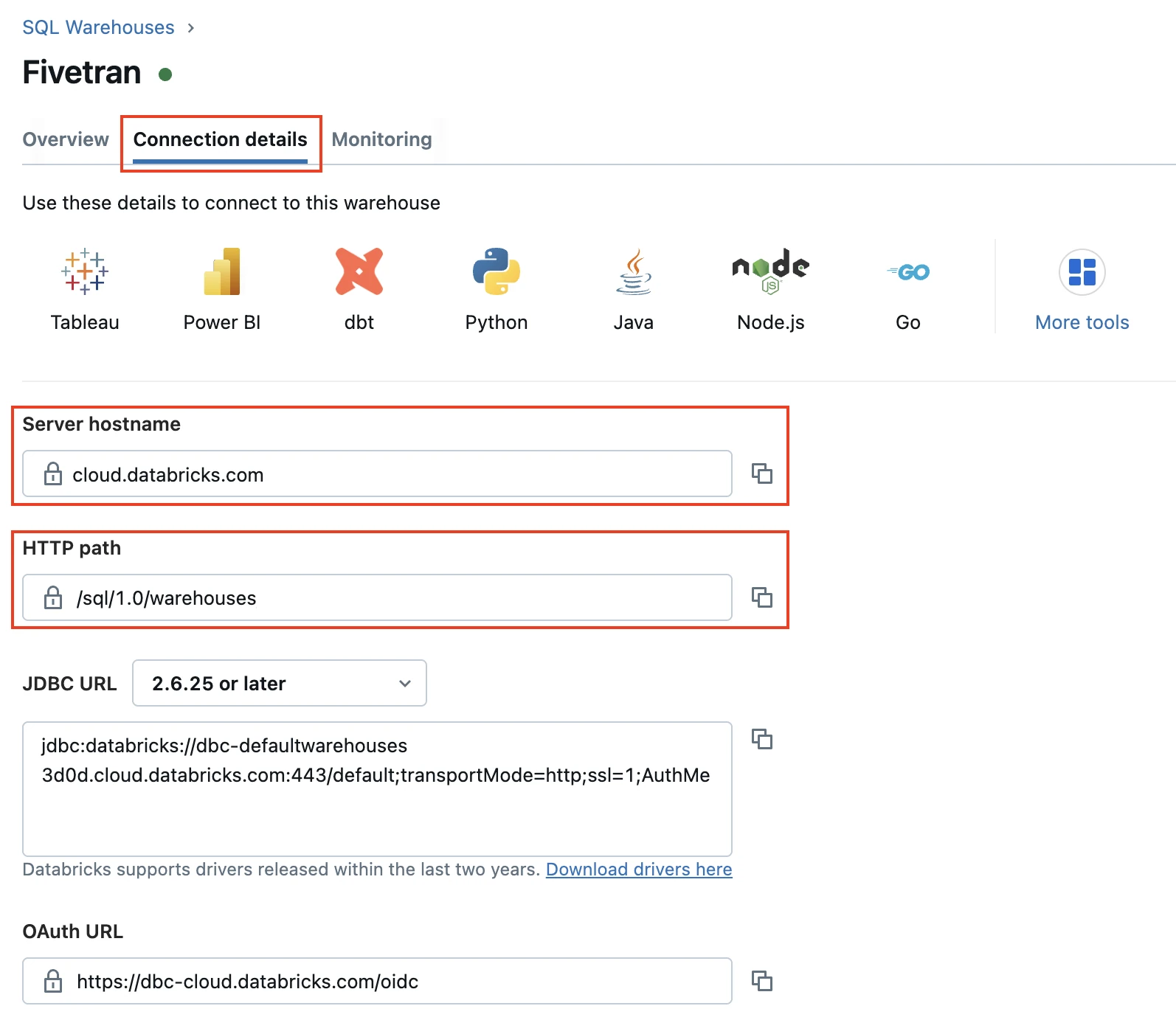
Make a note of the Server hostname and HTTP path. You will need them to configure Fivetran.
Choose authentication type
You can use one of the following authentication types for Fivetran to connect to Databricks:
Databricks personal access token authentication: Supports all Databricks destinations
OAuth machine-to-machine (M2M) authentication: Supports the Databricks destinations that are not connected to Fivetran using AWS PrivateLink or Azure Private Link
Configure Databricks personal access token authentication
To use the Databricks personal access token authentication type, create a personal access token by following the instructions in Databricks' personal access token authentication documentation.
If you do not use Unity Catalog, the user or service principal you want to use to create your access token must have the following privileges on the schema:
- SELECT
- MODIFY
- READ_METADATA
- USAGE
- CREATE
If you use Unity Catalog, the user or service principal you want to use to create your access token must have the following privileges on the catalog:
- CREATE SCHEMA
- CREATE TABLE
- MODIFY
- SELECT
- USE CATALOG
- USE SCHEMA
To enable Fivetran to add primary key and foreign key constraints, also grant
MANAGEon each table, schema, or catalog. For more information, see Primary key and foreign key constraints.If you use Unity Catalog to create external tables in a Unity Catalog-managed external location, the user or service principal you want to use to create your access token must have the following privileges:
On the external location:
- CREATE EXTERNAL TABLE
- READ FILES
- WRITE FILES
On the storage credentials:
- CREATE EXTERNAL TABLE
- READ FILES
- WRITE FILES
When you grant a privilege on the catalog, it is automatically granted to all current and future schemas in the catalog. Similarly, the privileges that you grant on a schema are inherited by all current and future tables in the schema.
Configure OAuth machine-to-machine (M2M) authentication
To use the OAuth machine-to-machine (M2M) authentication type, create your OAuth Client ID and Secret by following the instructions in Databricks' OAuth machine-to-machine (M2M) authentication documentation.
You cannot use this authentication type if you connect your destination to Fivetran using AWS PrivateLink or Azure Private Link.
Configure external staging for Hybrid Deployment
Skip to the next step if you want to use Fivetran's cloud environment to sync your data. Perform this step only if you want to use the Hybrid Deployment model for your data pipeline.
Configure one of the following external storages to stage your data before writing it to your destination:
Amazon S3 bucket (recommended)
Create Amazon S3 bucket
Create an S3 bucket by following the instructions in AWS documentation.
Fivetran stages data in the S3 bucket using server-side encryption with customer-provided keys (SSE-C). By default, buckets created in the AWS console block SSE-C uploads.
In the bucket settings, go to Properties > Default encryption and make sure SSE-C (server-side encryption with customer-provided keys) is not selected under Blocked encryption types.
If the bucket blocks SSE-C uploads, the Validate Permissions setup test fails with the following error, even when the IAM credentials are valid:
Invalid storage container credentials, please check the key and secret provided for LDP
Create IAM policy for S3 bucket
Log in to the Amazon IAM console.
Go to Policies, and then click Create policy.
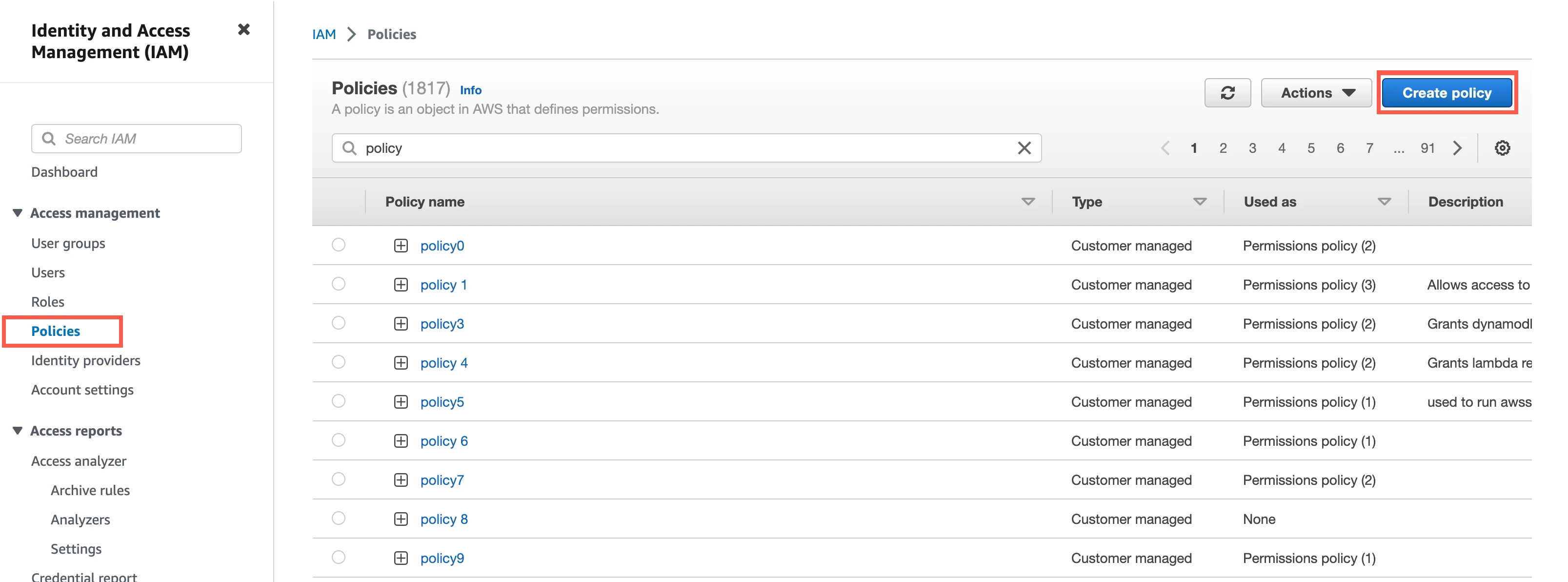
Go to the JSON tab.
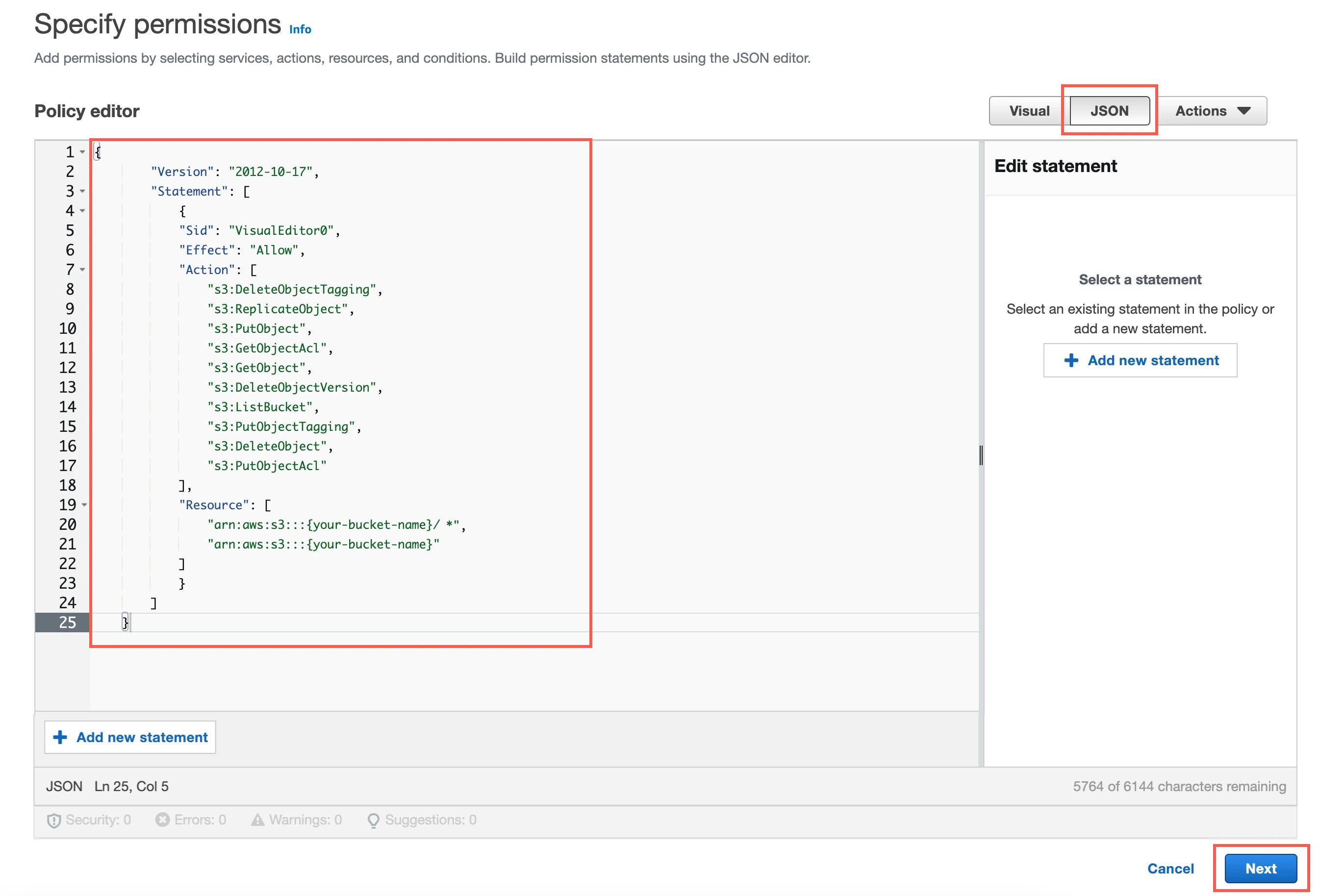
Copy the following policy and paste it in the JSON editor.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:DeleteObjectTagging", "s3:ReplicateObject", "s3:PutObject", "s3:GetObjectAcl", "s3:GetObject", "s3:DeleteObjectVersion", "s3:ListBucket", "s3:PutObjectTagging", "s3:DeleteObject", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::{your-bucket-name}/*", "arn:aws:s3:::{your-bucket-name}" ] } ] }In the policy, replace
{your-bucket-name}with the name of your S3 bucket.Click Next.
Enter a Policy name.
Click Create policy.
(Optional) Configure IAM role authentication
- Perform this step only if you want us to use AWS Identity and Access Management (IAM) to authenticate the requests in your S3 bucket. Skip to the next step if you want to use IAM user credentials for authentication.
- To authenticate using IAM, your Hybrid Deployment Agent must run on an EC2 instance in the account associated with your S3 bucket.
In the Amazon IAM console, go to Roles, and then click Create role.
Select AWS service.
In Service or use case drop-down menu, select EC2.
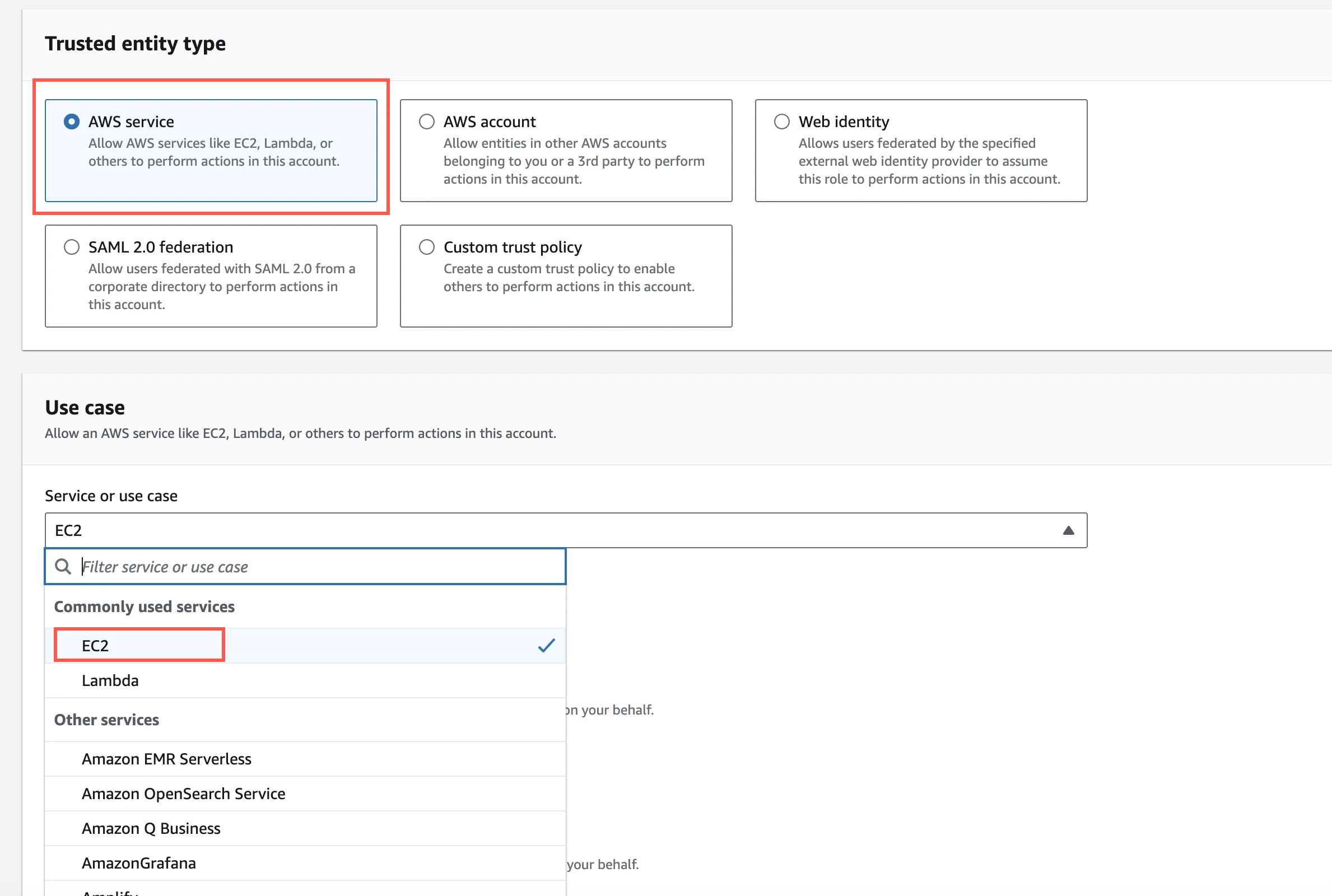
Click Next.
Select the checkbox for the IAM policy you created for your S3 bucket.
Click Next.
Enter the Role name and click Create role.
In the Amazon IAM console, go to the EC2 service.
Go to Instances, and then select the EC2 instance hosting your Hybrid Deployment Agent.
In the top right corner, click Actions and go to Security > Modify IAM role.
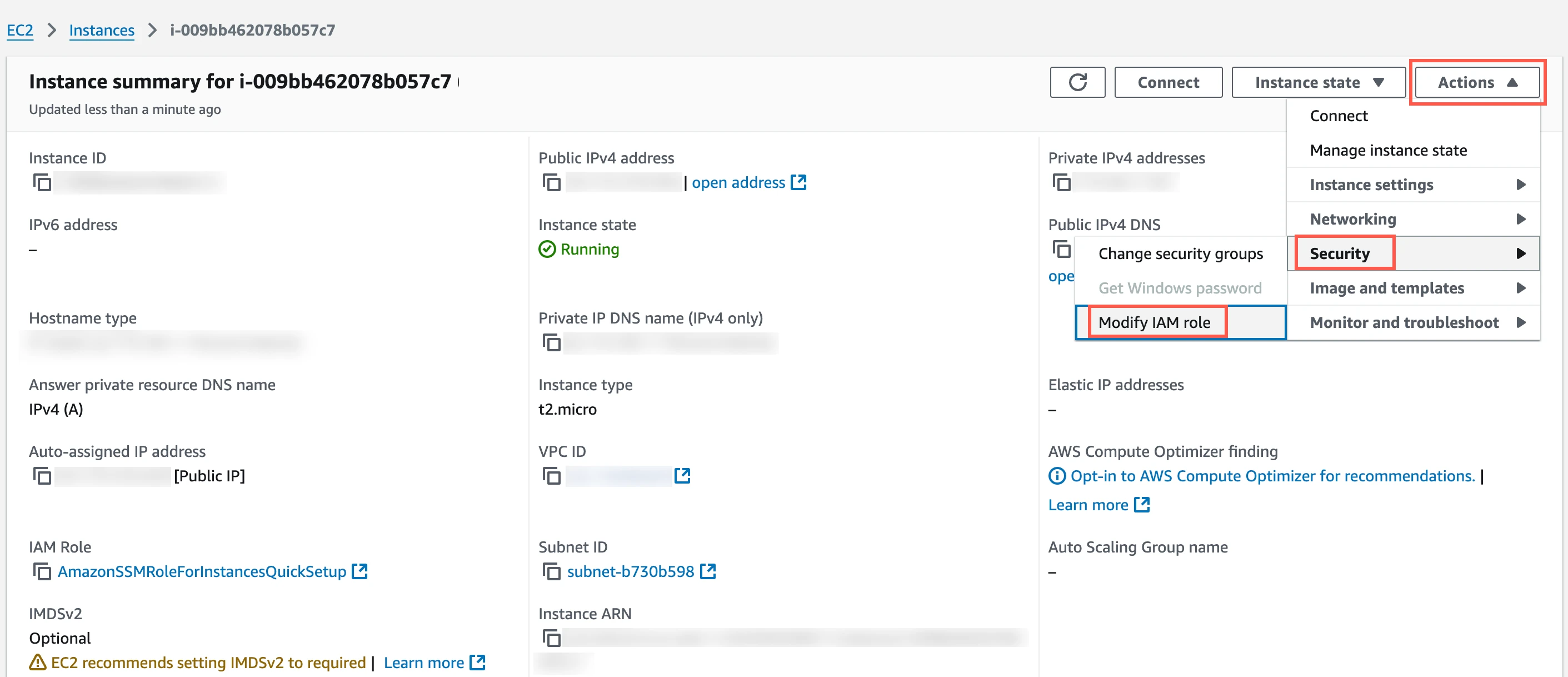
In the IAM role drop-down menu, select the new IAM role you created and click Update IAM role.
(Optional) Configure IAM user authentication
Perform this step only if you want us to use IAM user credentials to authenticate the requests in your S3 bucket.
In the Amazon IAM console, go to Users, and then click Create user.
Enter a User name, and then click Next.
Select Attach policies directly.
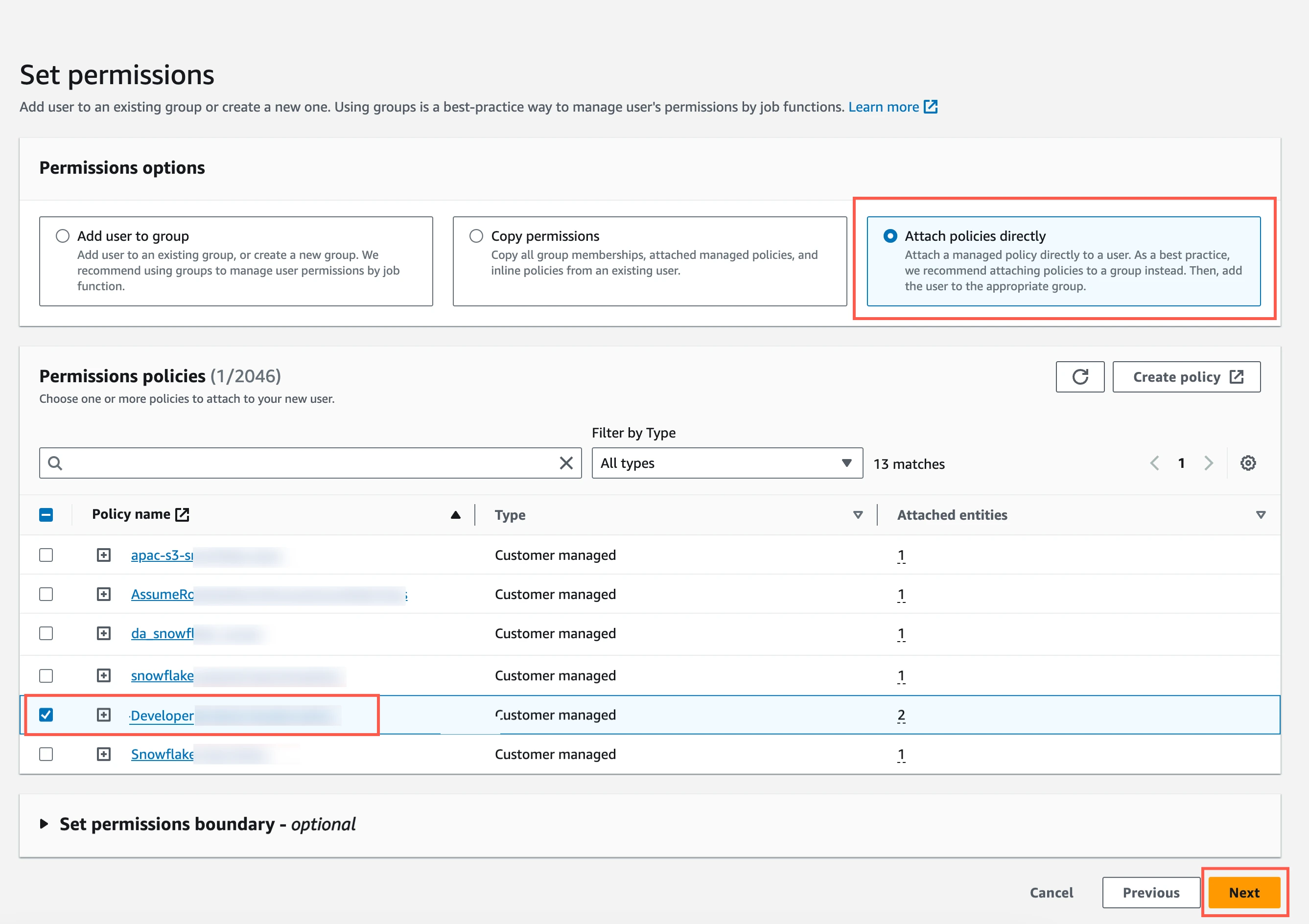
Select the checkbox next to the policy you created in the Create IAM policy for S3 bucket step, and then click Next.
In the Review and create page, click Create user.
In the Users page, select the user you created.
Click Create access key.
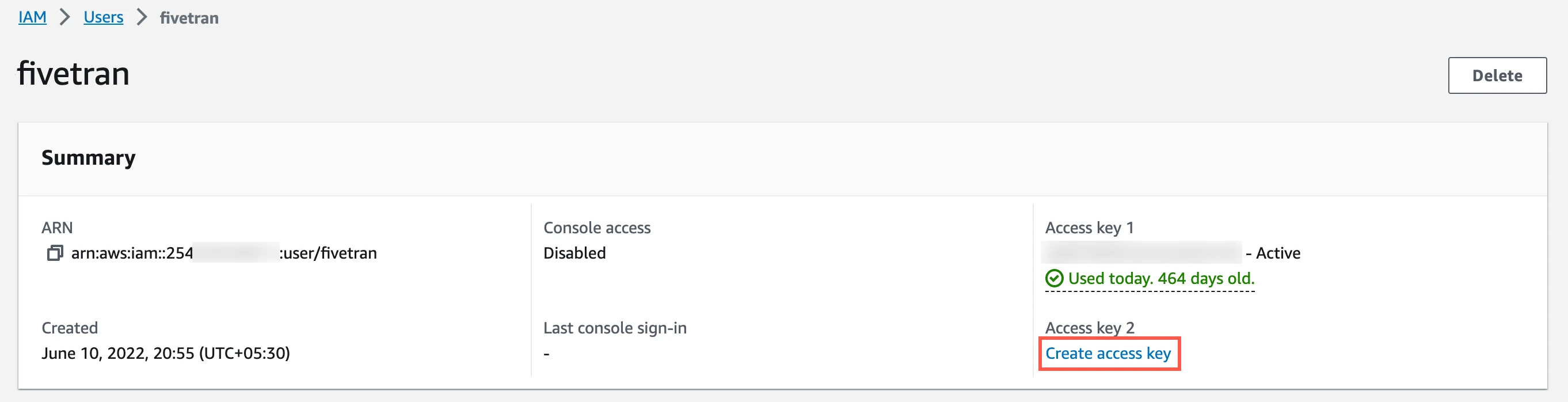
Select Application running outside AWS, and then click Next.
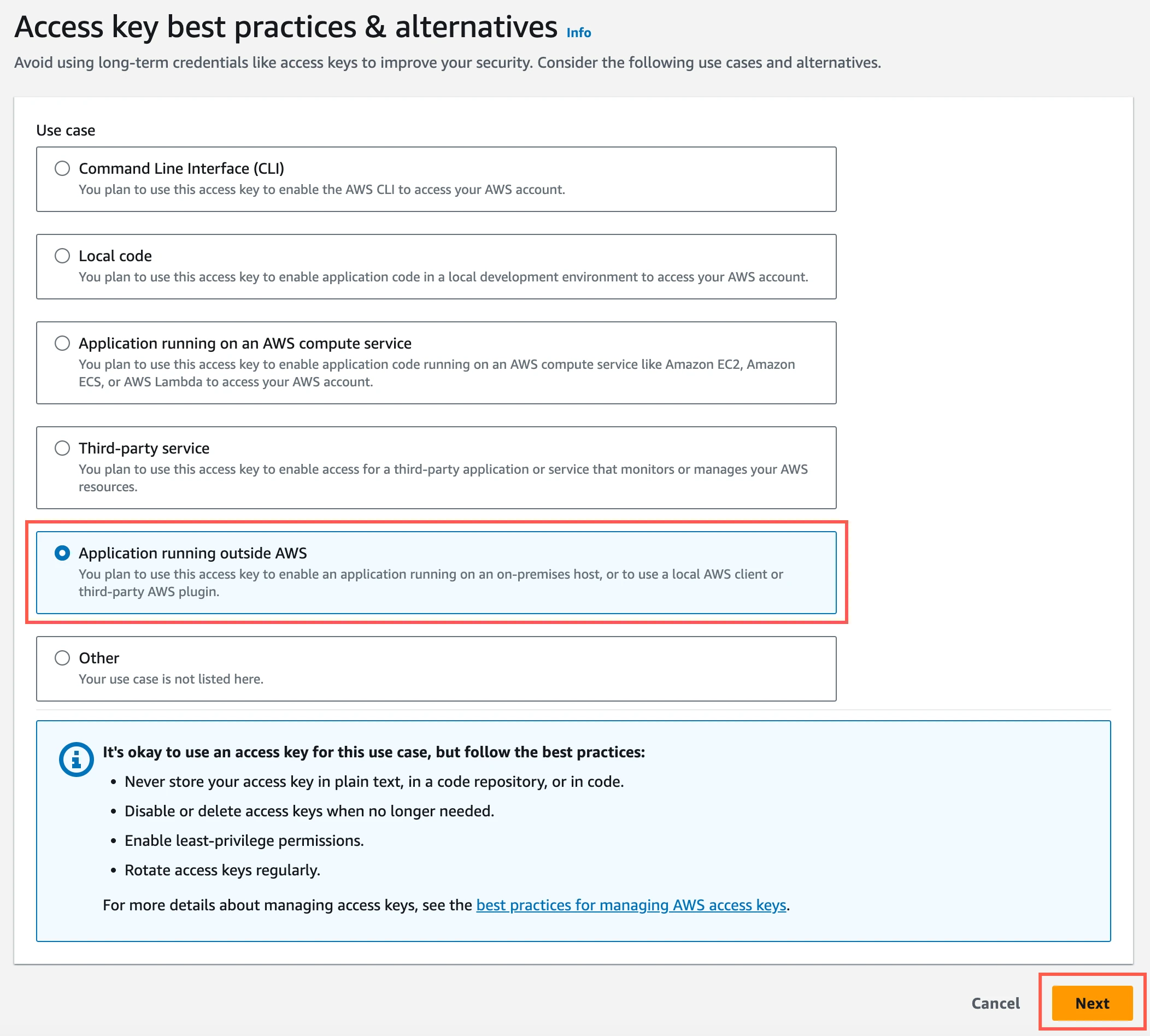
Click Create access key.
Click Download .csv file to download the Access key ID and Secret access key to your local drive. You will need them to configure Fivetran.
Azure Blob storage container
Create Azure storage account
Create an Azure storage account by following the instructions in Azure documentation. When creating the account, make sure you do the following:
In the Advanced tab, select the Require secure transfer for REST API operations and Enable storage account key access checkboxes.
In the Permitted scope for copy operations drop-down menu, select From any storage account.
In the Networking tab, select one of the following Network access options:
- If your Databricks destination is not hosted on Azure or if your storage container and destination are in different regions, select Enable public access from all networks.
- If your Databricks destination is hosted on Azure and if it is in the same region as your storage container, select Enable public access from selected virtual networks and IP addresses.
Ensure the virtual network or subnet where your Databricks workspace or cluster resides is included in the allowed list for public access on the Azure storage account.
In the Encryption tab, choose Microsoft-managed keys (MMK) as the Encryption type.
Find storage account name and access key
Log in to the Azure portal.
Go to your storage account.
On the navigation menu, click Access keys under Security + networking.
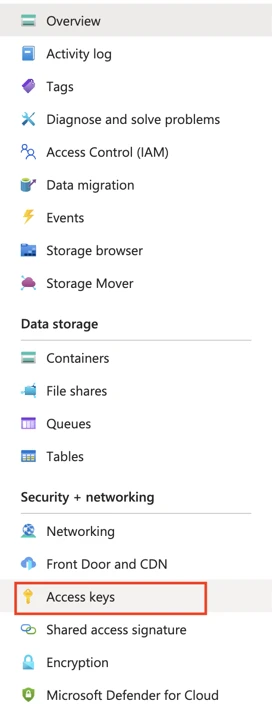
Make a note of the Storage account name and Key. You will need them to configure Fivetran.
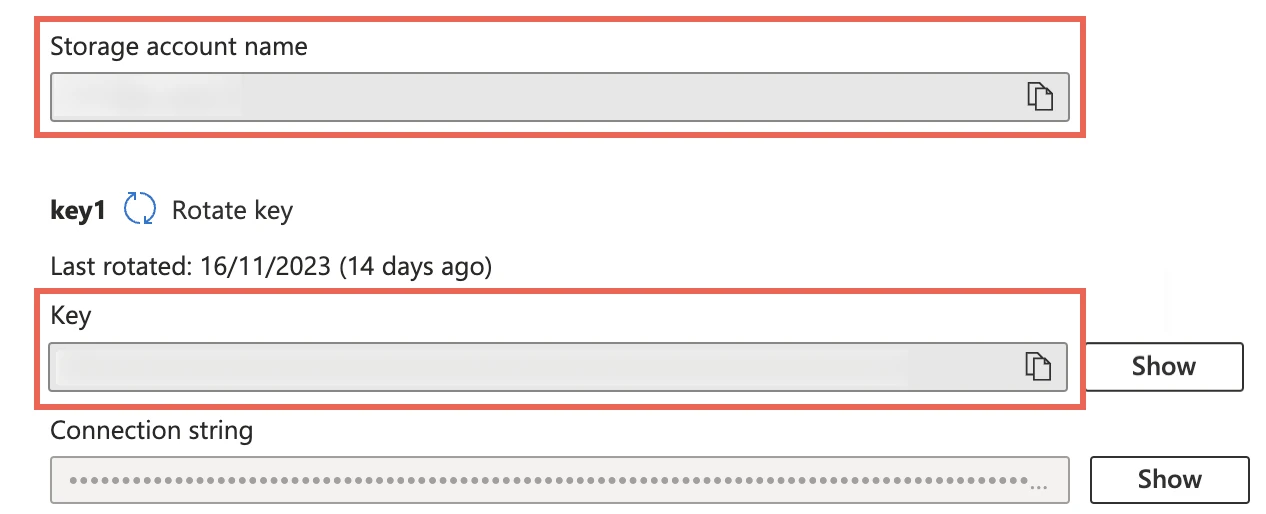
As a security best practice, do not save your access key and account name anywhere in plain text that is accessible to others.
(Optional) Configure service principal for authentication
Perform the steps in this section only if you want to configure service principal (client credentials) authentication for your Azure Blob storage container. Skip to the next step if you want to use your storage account credentials for authentication.
Register application and add service principal
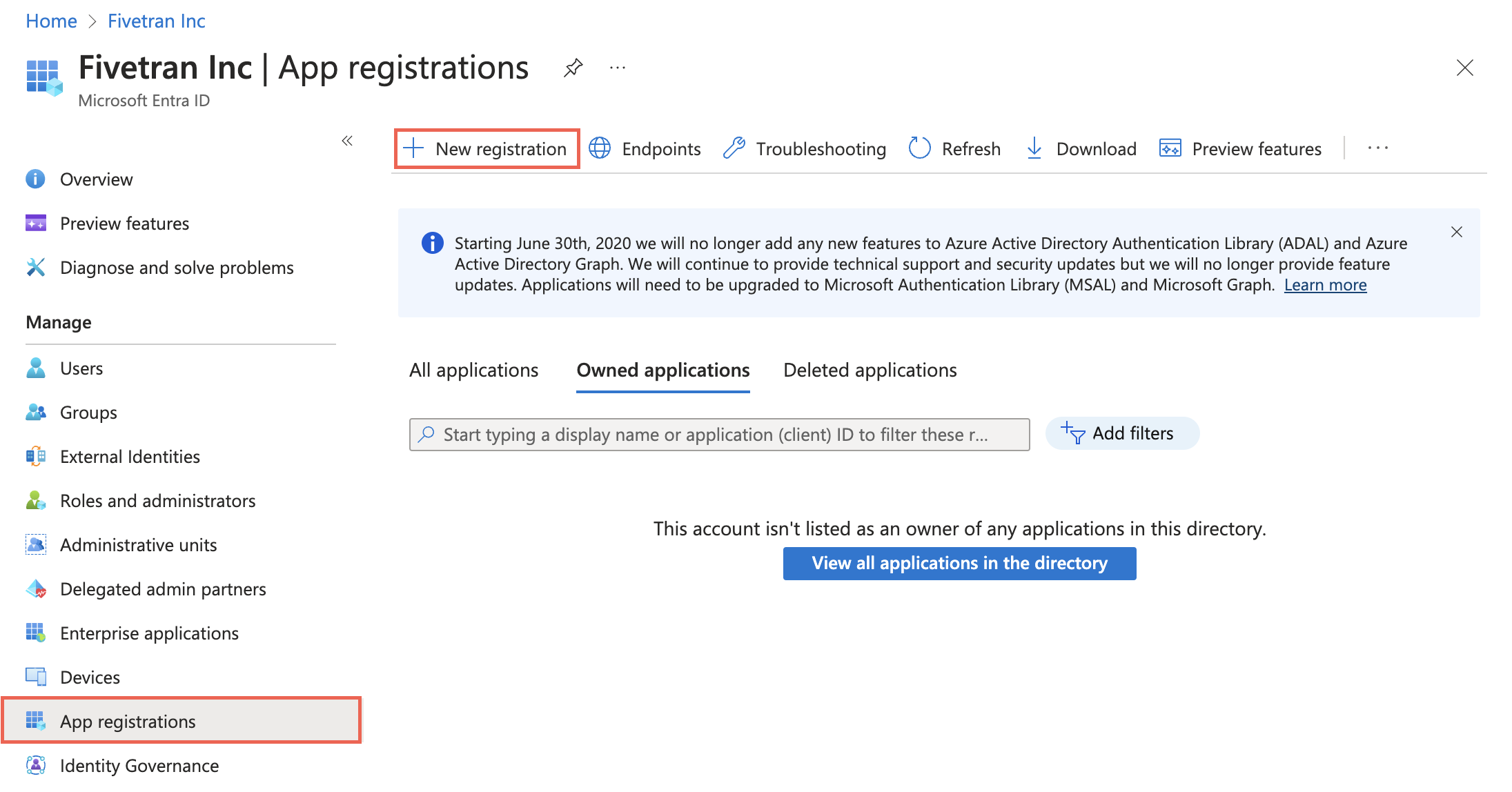
On the navigation menu, select Microsoft Entra ID (formerly Azure Active Directory).
Go to App registrations and click + New registration.
Enter a Name for the application.
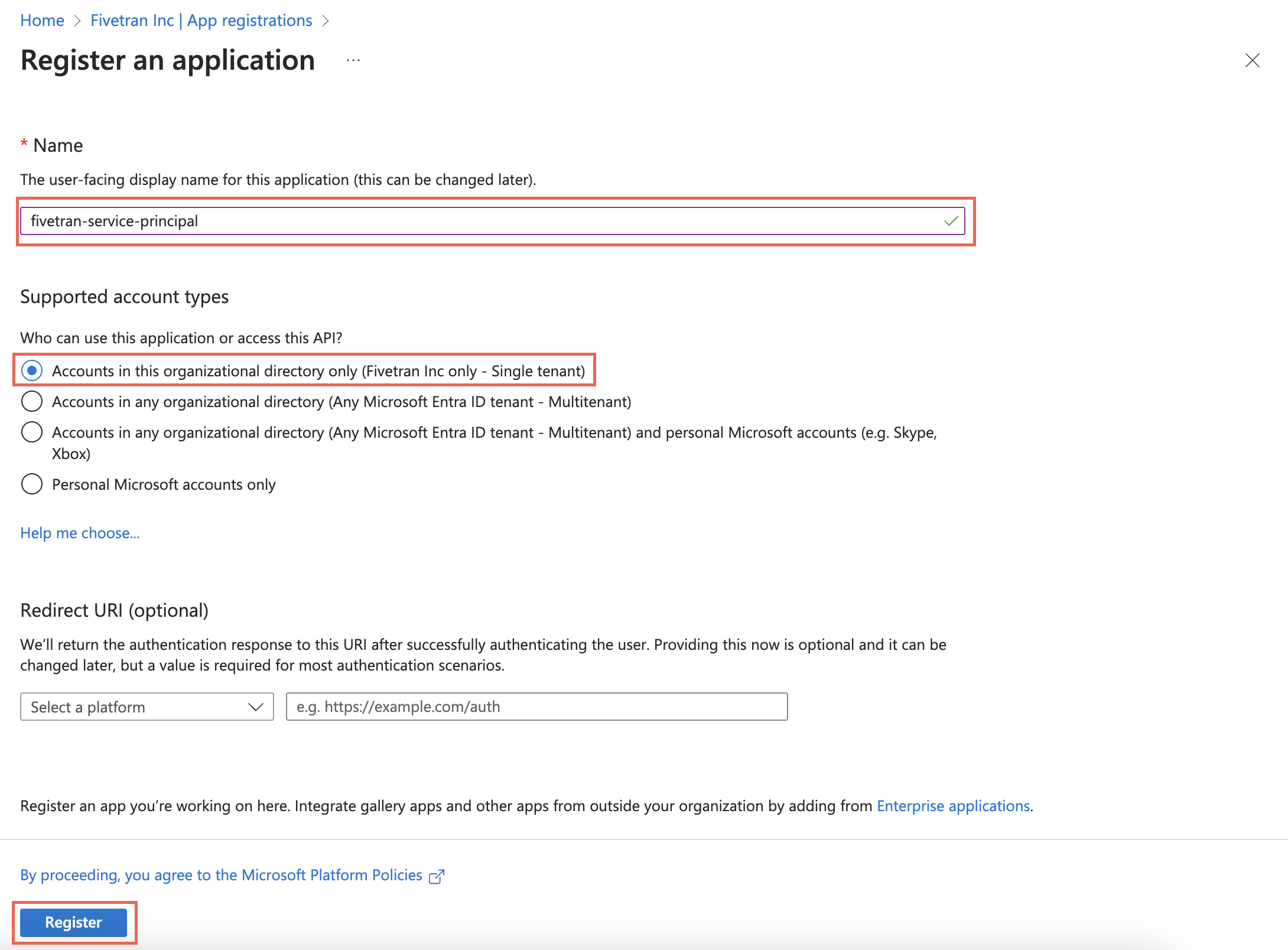
In the Supported account types section, select Accounts in this organizational directory only and click Register.
Make a note of the Application (client) ID and Directory (tenant) ID. You will need them to configure Fivetran.
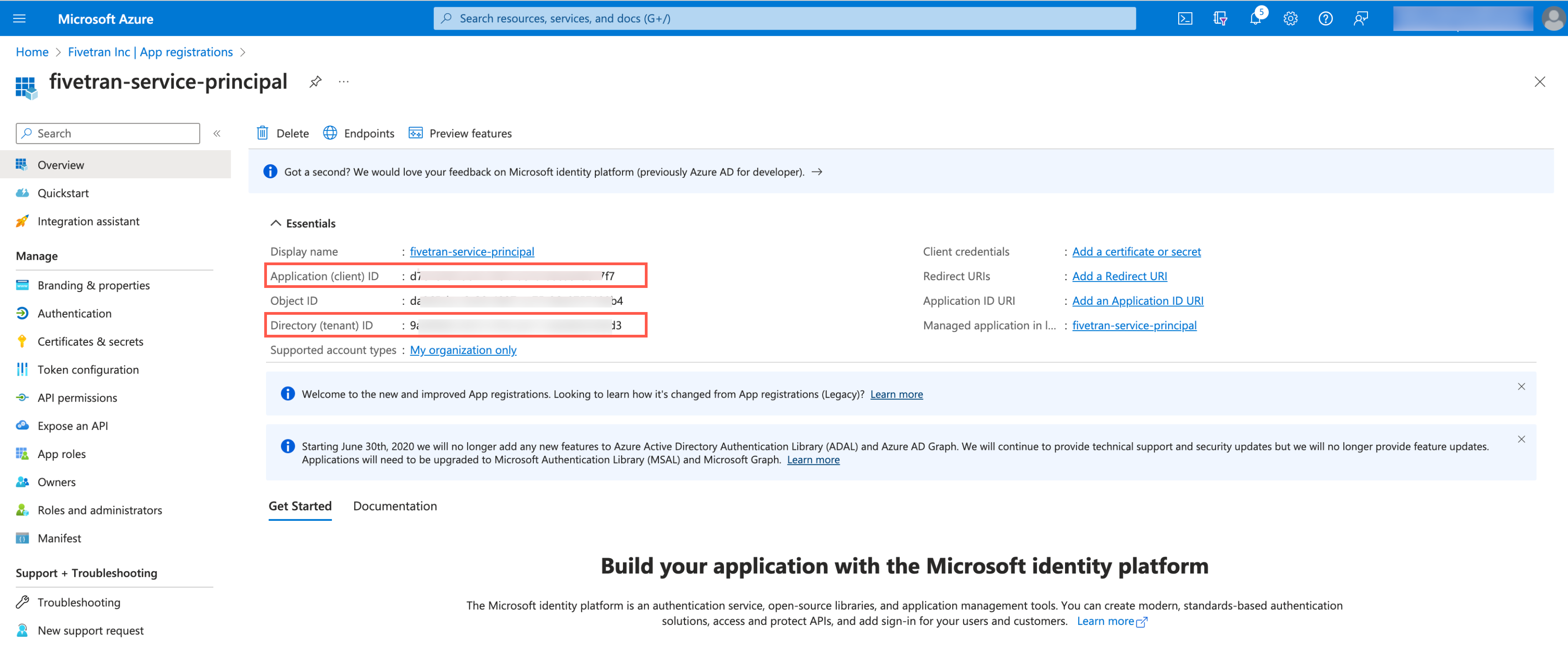
Create client secret
Select the application you registered.
On the navigation menu, go to Certificates & secrets and click + New client secret.
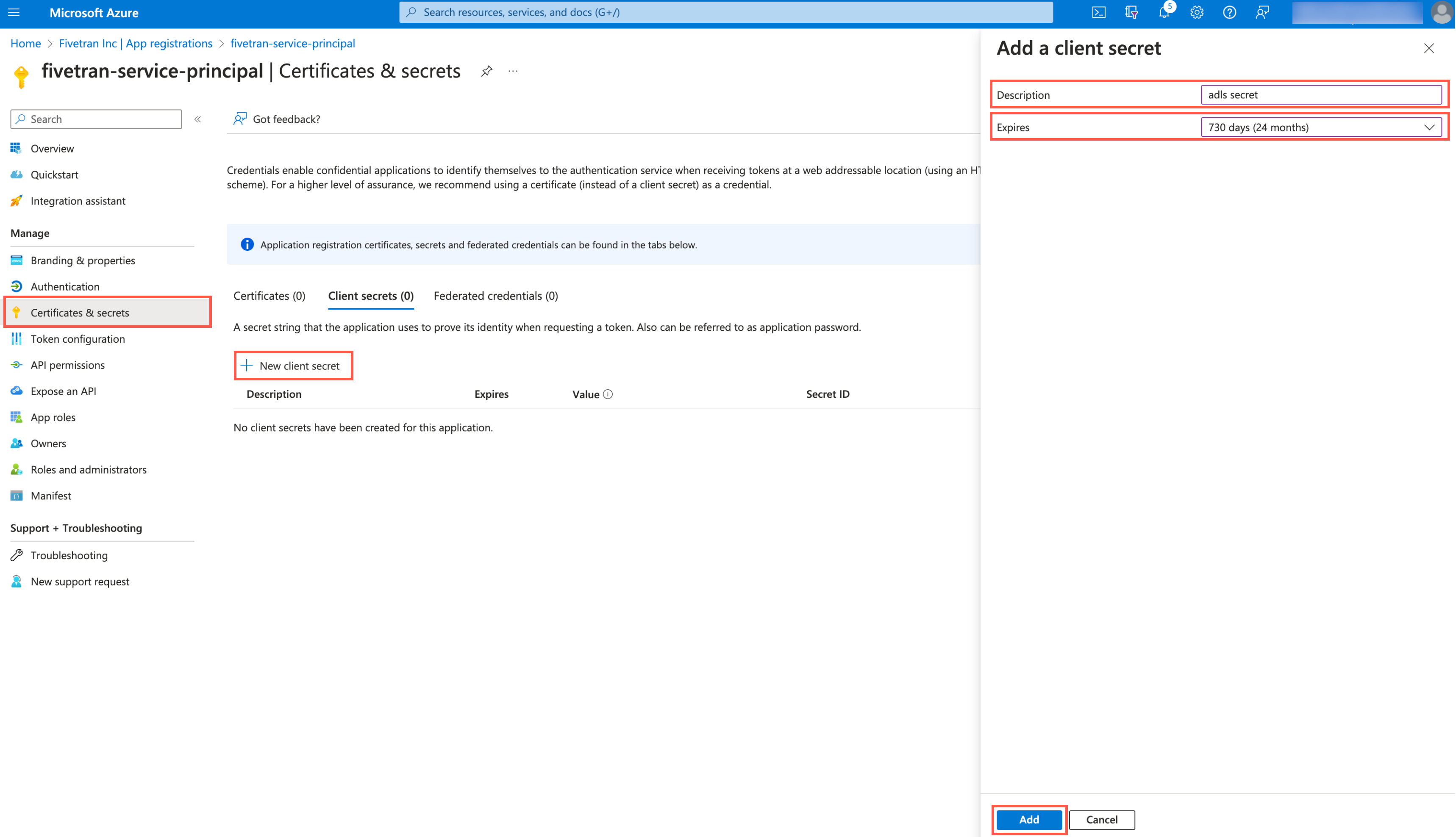
Enter a Description for your client secret.
In the Expires drop-down menu, select an expiry period for the client secret.
Click Add.
Make a note of the client secret. You will need it to configure Fivetran.
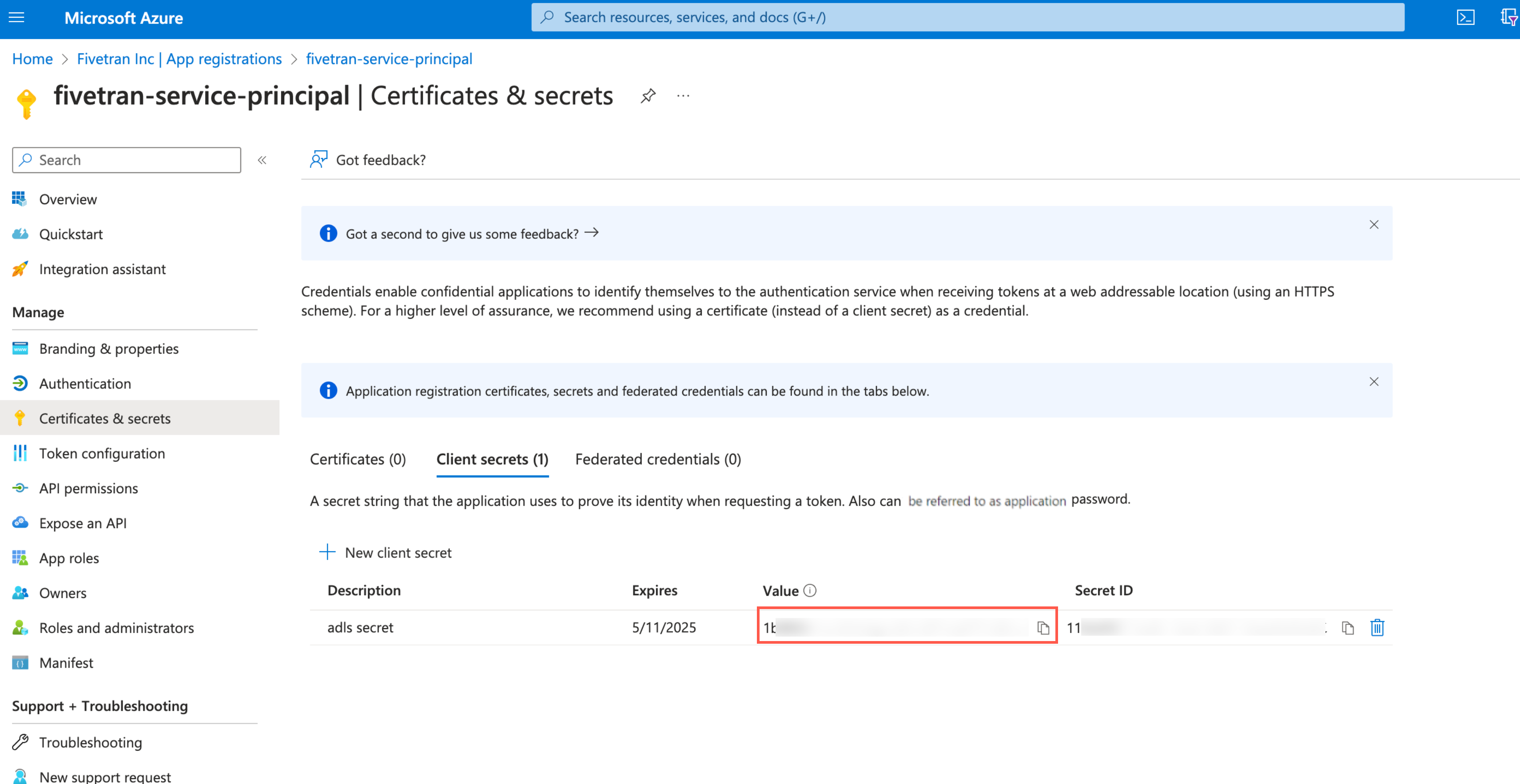
Assign role to storage account
You must assign the Storage Blob Delegator role at the storage account level because the service principal issues a User Delegation SAS token. We need this token to access the container, and although the SAS is scoped to a specific container, it can generate the token only when the role assignment exists at the storage account level.
Go to the storage account you created.
On the navigation menu, click Access Control (IAM).
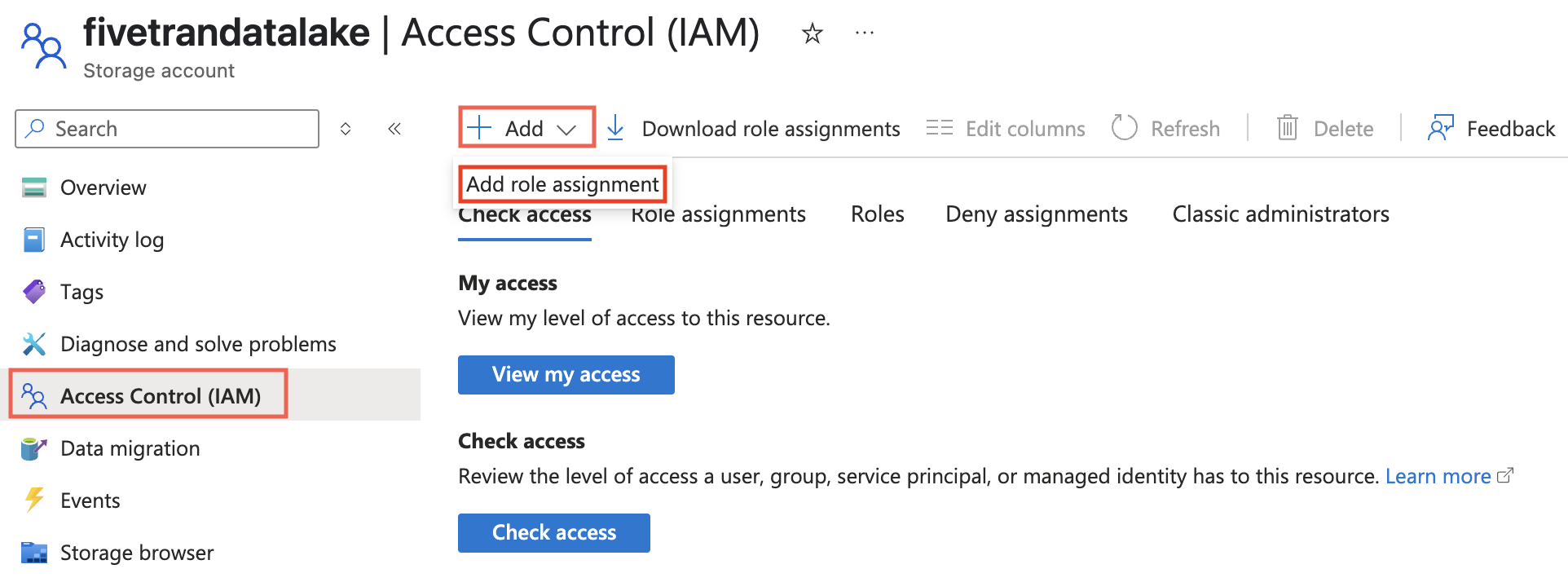
Click Add and select Add role assignment.
In the Role tab, select Storage Blob Delegator and click Next.
In the Members tab, select User, group, or service principal.
Click + Select members.
In the Select members pane, select the service principal you added and then click Select.
Click Review + assign.
Assign role to container
Go to your ADLS container and select Access Control (IAM).
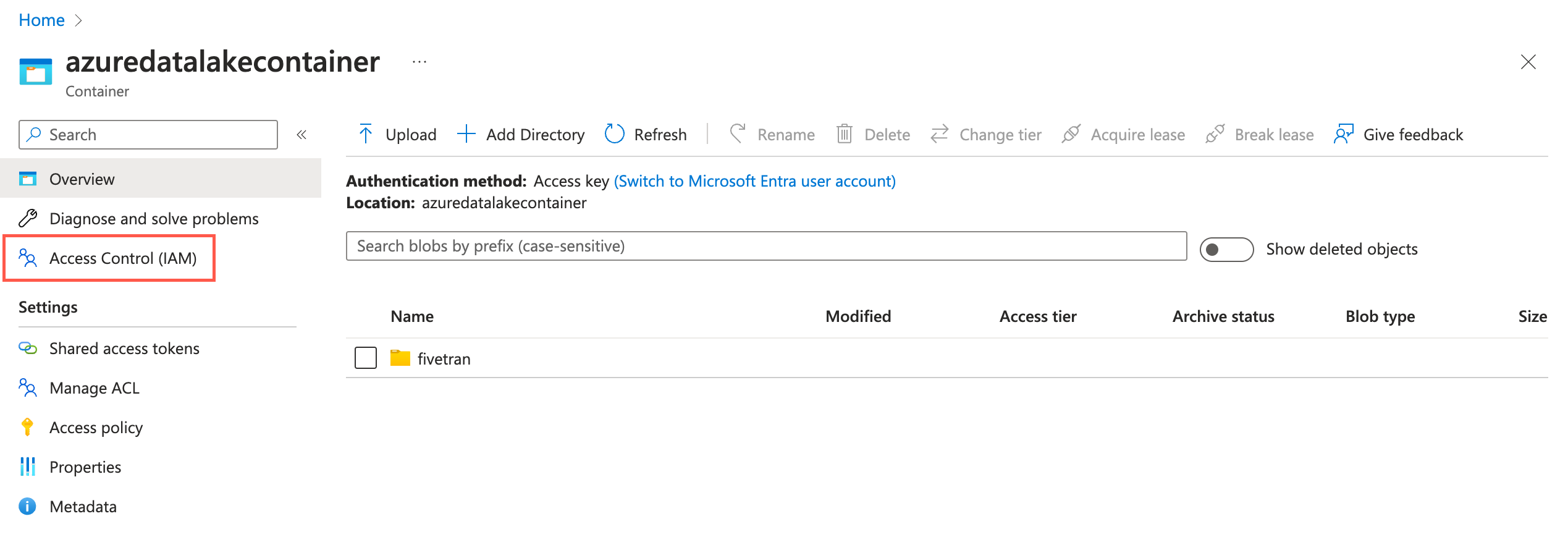
Click Add and then select Add role assignments.
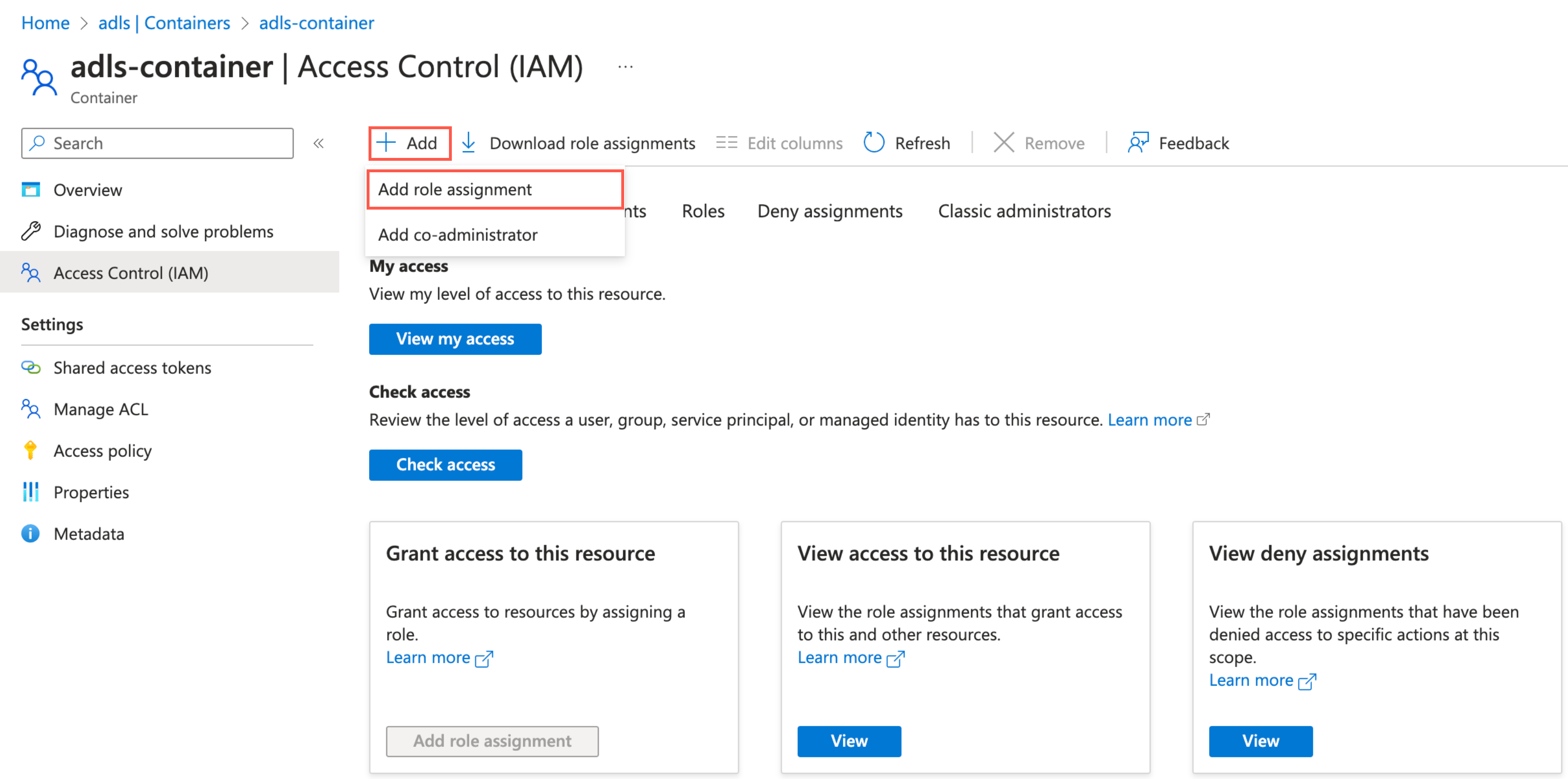
In the Role tab, select Storage Blob Data Contributor and click Next.
In the Member tab, select User, group, or service principal.
Click + Select members.
In the Select members pane, select the service principal you added and then click Select.
Click Review + assign.
Choose connection method
Decide whether to connect Fivetran to your Databricks destination directly or using AWS PrivateLink.
Connect directly
This is the simplest connection method where Fivetran connects directly to your Databricks destination. This is the default connection method and you do not have to set up or configure anything to use it.
Connect using AWS PrivateLink
You must have a Business Critical plan to use AWS PrivateLink.
AWS PrivateLink allows VPCs and AWS-hosted or on-premises services to communicate with one another without exposing traffic to the public internet. PrivateLink is the most secure connection method. Learn more in AWS PrivateLink documentation.
How it works:
Fivetran accesses the data plane in your AWS account using the control plane network in Databricks' account.
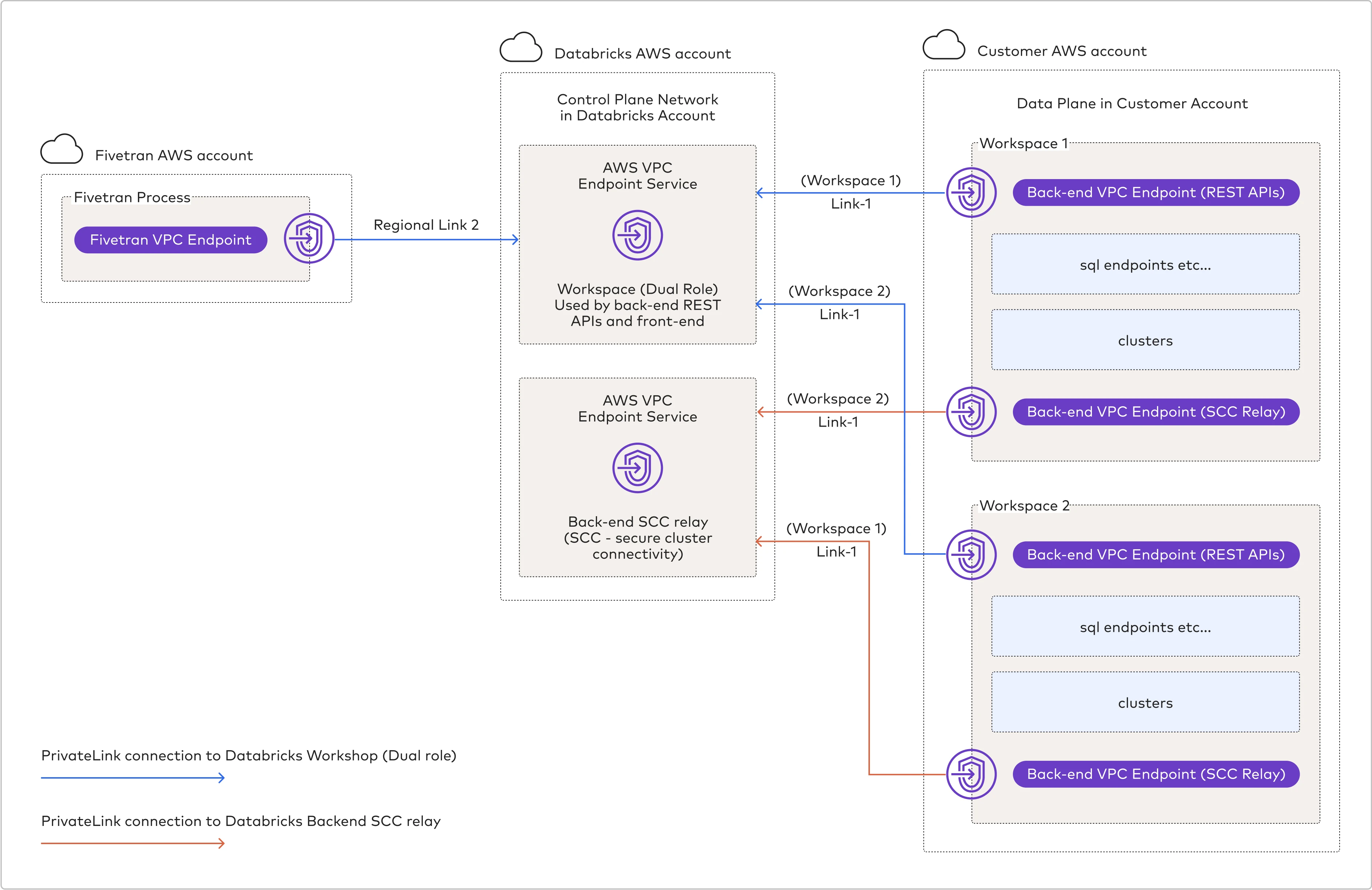
You set up a back-end AWS PrivateLink connection between your AWS account and Databricks' AWS account (shown as
(Workspace 1/2) Link-1in the diagram above).Fivetran creates and maintains a front-end AWS PrivateLink connection between Fivetran's AWS account and Databricks' AWS account (shown as
Regional - Link-2in the diagram above).
Prerequisites
To set up AWS PrivateLink, you need:
- A Fivetran instance configured to run in AWS
- A Databricks destination in one of our supported regions
- All of Databricks' requirements
Configure AWS PrivateLink
Follow Databricks' Enable AWS PrivateLink documentation to enable private connectivity for your workspaces. Your workspaces must have the following:
- A registered back-end VPC endpoint for secure cluster connectivity relay
- A registered back-end VPC endpoint for REST APIs
- A PAS object with access to Fivetran's VPC endpoints
- If the Private Access Level on the PAS object is set to Account, a Fivetran VPC endpoint (for the applicable AWS region) that's registered once per account
- If the Private Access Level on the PAS object is set to Endpoint, a Fivetran VPC endpoint (for applicable AWS region) that's registered using the
allowed_vpc_endpoint_idsproperty
Register Fivetran endpoint details
Register the Fivetran endpoint for the applicable AWS region with your Databricks workspaces. We cannot access your workspaces until you do so.
| AWS Region | VPC endpoint |
|---|---|
| ap-south-1 Asia Pacific (Mumbai) | vpce-089f13c9231c2b729 |
| ap-southeast-1 Asia Pacific (Singapore) | vpce-03f0abf5b0d840936 |
| ap-southeast-2 Asia Pacific (Sydney) | vpce-0e5f79a1613d0cf05 |
| ap-northeast-2 Asia Pacific (Seoul) | vpce-08125a2271630478c |
| ca-central-1 Canada (Central) | vpce-09f0049f9a92177f1 |
| eu-central-1 Europe (Frankfurt) | vpce-049699737170c880d |
| eu-west-1 Europe (Ireland) | vpce-0b32cb6c08f6fe0df |
| eu-west-2 Europe (London) | vpce-03fde3e4804f537eb |
| us-east-1 US East (N. Virginia) | vpce-0ff9bd04153060180 |
| us-east-2 US East (Ohio) | vpce-05153aa99bf7a4575 |
| us-west-2 US West (Oregon) | vpce-0884ff0f23dcbf0dc |
Regardless of your Fivetran subscription plan, if you have enabled back-end AWS PrivateLink connection between your AWS account and Databricks' AWS account (shown as (Workspace 1/2) Link-1 in the diagram above), you must register the Fivetran endpoint (for the applicable AWS region) to avoid connection failures.
Complete Fivetran configuration
Log in to your Fivetran account.
Go to the Destinations page and click Add destination.
Enter a Destination name of your choice and then click Add.
Select Databricks as the destination type.
(Enterprise and Business Critical accounts only) Select the deployment model of your choice:
- SaaS Deployment
- Hybrid Deployment
If you selected Hybrid Deployment, click Select Hybrid Deployment Agent and do one of the following:
- To use an existing agent, select the agent you want to use, and click Use Agent.
- To create a new agent, click Create new agent and follow the setup instructions specific to your container platform.
(Hybrid Deployment only) Choose the container service (external storage) you configured to stage your data.
If you chose AWS S3, in the Authentication type drop-down menu, select the authentication type you configured for your S3 bucket.
If you selected IAM_ROLE, enter the name and region of your S3 bucket.
If you selected IAM_USER, enter the following details of your S3 bucket:
- Name
- Region
- AWS access key ID
- AWS secret access key
If you chose Azure Blob Storage, in the Authentication type drop-down menu, select the authentication type you configured for your Azure Blob Storage container.
If you selected Storage Account Key, enter the storage account name and storage account key you found.
If you selected Client Credentials, enter the following details:
- Storage account name
- Client ID and client secret of your service principal
- Tenant ID of your service principal
(Not applicable to Hybrid Deployment) Choose your Connection Method:
- Connect directly
- Connect via PrivateLink
The Connect via PrivateLink option is only available for Business Critical accounts.
(Unity Catalog only) Enter the Catalog name. This is the name of the catalog in Unity Catalog, such as
fivetranormain.Enter the Server Hostname.
If we auto-detect your Databricks Deployment Cloud, the Databricks Deployment Cloud field won't be visible in the setup form.
Enter the default Port number,
443.Enter the HTTP Path.
(Optional, Private Preview only) If you want to manage your credentials outside of Fivetran, enable the Use External Secrets Manager toggle. For some connectors and destinations, this toggle only appears after you select a credential-based authentication method. See the External Secret Managers documentation for more information.
- If you have already configured External Secret Managers for your account, select one from the drop-down menu. Note that the list is filtered by the deployment model of the destination: if the destination uses SaaS Deployment, External Secret Managers configured for Hybrid Deployment won't be available, and vice versa.
- To edit the details of the selected External Secret Manager, click Edit manager details in Account Settings.
- To set up a new External Secret Manager, click Configure a new secrets manager. See the Create New External Secret Manager documentation for prerequisites and setup instructions.
- You can manage all your External Secret Managers at any time under Account Settings. See the External Secret Managers documentation for more information.
- When ESM is enabled, credential fields are replaced by ESM key fields. In each ESM key field, enter the name of the secret stored in your external secrets manager that corresponds to that credential — not the credential value itself. For more information, see External Secret Managers.
Specify the authentication details for your destination.
- If you selected Connect directly as the connection method, in the Authentication Type drop-down menu, select the authentication type you want Fivetran to connect to your destination. If you selected PERSONAL ACCESS TOKEN in the drop-down menu, enter the Personal Access Token you created. If you selected OAUTH 2.0 in the drop-down menu, enter the OAuth 2.0 Client ID and OAuth 2.0 Secret you created.
- If you selected Connect via PrivateLink as the connection method, enter the Personal Access Token you created.
(Optional) Set the Create Delta tables in an external location toggle to ON to create Delta tables as external tables. You can:
You cannot edit the toggle and external location path after you save the setup form.
Enter the External Location you want to use. We will create the Delta tables in the
{externallocation}/{schema}/{table}path.Use the default Databricks File System location registered with the cluster. Do not specify the external location. We will create the external Delta tables in the
/{schema}/{table}path.
Private Preview (Optional) Set the Create volumes in an external location toggle to ON to create volumes in external location.
- Databricks Volume feature is only supported on Unity catalog.
- You cannot edit the toggle and external volume location path after you save the setup form.
- The user or service principal must have the CREATE VOLUME privilege granted at the schema level to create volumes. Databricks recommends granting this privilege at the schema level. You can also grant this privilege on a catalog to allow the user to create volumes in any existing or future schema in the catalog.
- Enter the External Volume Location you want to use. Specify your external volume location to sync unstructured files in an external location. We will sync the unstructured files in the
{External Volume Location from UI}/Volumes/{schema}/{table}path.
Be sure not to use "volume", "volumes", or "tables" as keywords for catalog, schema, and table names when syncing unstructured files.
(Optional) Set the Disable VACUUM operations toggle to ON to stop Fivetran from running VACUUM operations on your Databricks tables. By default, the toggle is set to OFF, and Fivetran automatically runs VACUUM operations during scheduled table cleanup to optimize storage.
- Disabling the VACUUM operations may increase storage usage over time as old file versions accumulate.
- You can update this setting anytime after the initial setup.
Choose the Data processing location. Depending on the plan you are on and your selected cloud service provider, you may also need to choose a Cloud service provider and AWS region as described in our Destinations documentation.
Choose your Time zone.
(Optional for Business Critical accounts and SaaS Deployment) To enable regional failover, set the Use Failover toggle to ON, and then select your Failover Location and Failover Region. Make a note of the IP addresses of the secondary region and safelist these addresses in your firewall.
Click Save & Test.
Fivetran tests and validates the Databricks connection. On successful completion of the setup tests, you can sync your data using Fivetran connectors to the Databricks destination.
In addition, Fivetran automatically configures a Fivetran Platform connection to transfer the connection logs and account metadata to a schema in this destination. The Fivetran Platform Connector enables you to monitor your connections, track your usage, and audit changes. The Fivetran Platform connection sends all these details at the destination level.
If you are an Account Administrator, you can manually add the Fivetran Platform connection on an account level so that it syncs all the metadata and logs for all the destinations in your account to a single destination. If an account-level Fivetran Platform connection is already configured in a destination in your Fivetran account, then we don't add destination-level Fivetran Platform connections to the new destinations you create.
(Optional) Store data in external locations
With Unity Catalog
You can customize where Fivetran stores Delta tables. If you use Unity Catalog, Fivetran creates managed tables in Databricks. Managed tables are stored in the root storage location that you configure when you create a metastore.
You can also instruct Fivetran to store tables in an external location managed by Unity Catalog. To do so, follow these steps:
- Follow Databricks' Manage storage credential guide to add a storage credential to Unity Catalog.
- Follow Databricks' Manage external location guide to add an external location to Unity Catalog.
- Enable Create Delta tables in an external location and specify the external location (for example,
s3://mybucket/myprefix) as the value.
Using Hive metastore
If you do not use Unity Catalog, you can still store Delta tables in a specific S3 bucket. First, you must create an AWS instance profile and associate it with Databricks compute.
See Databricks' Secure access to S3 buckets using instance profiles documentation. Perform the first four steps mentioned in the guide to create an instance profile.
In the Databricks console, click Settings > SQL Admin Console.
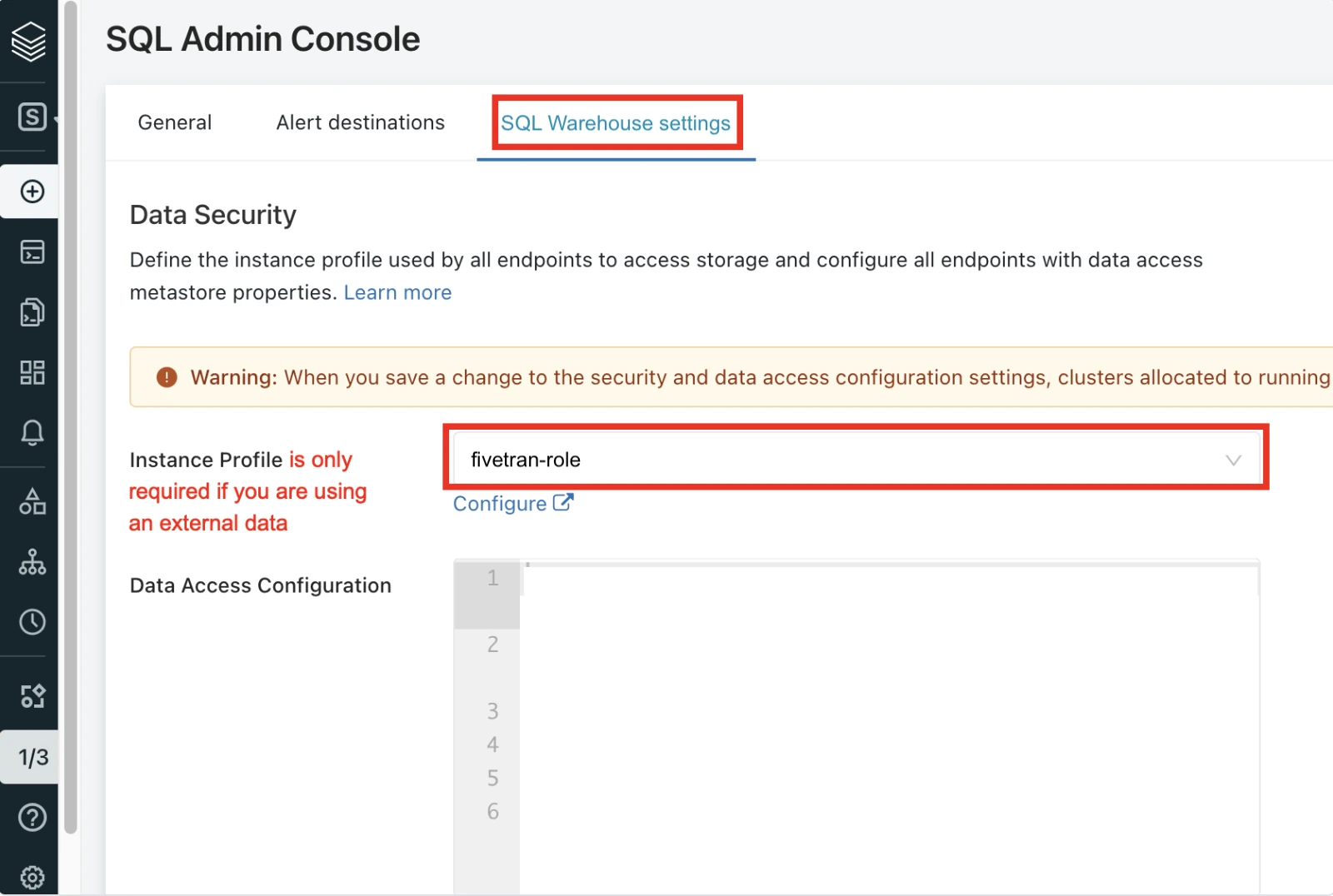
In the Settings window, select SQL Warehouse Settings.
Select the Instance profile you created above.
(Optional) Connect Databricks cluster
We strongly recommend using Databricks SQL warehouses with Fivetran. To learn more, skip to the Connect SQL warehouse step.
Log in to your Databricks workspace.
In the Databricks console, go to Data Engineering > Cluster > Create Cluster..
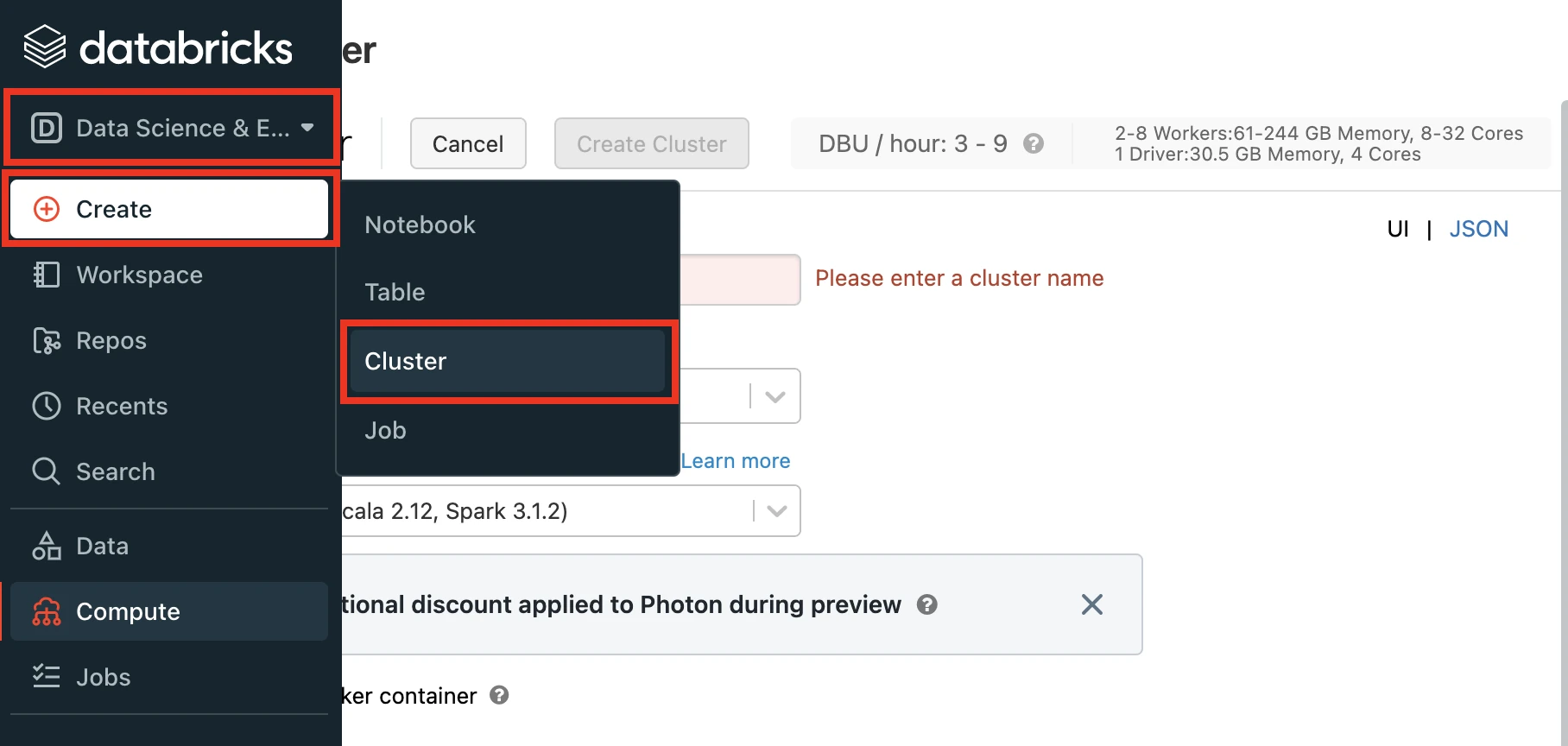
Enter a Cluster name of your choice.
Set the Databricks Runtime Version to the latest LTS release. At minimum, you must choose v7.3+.
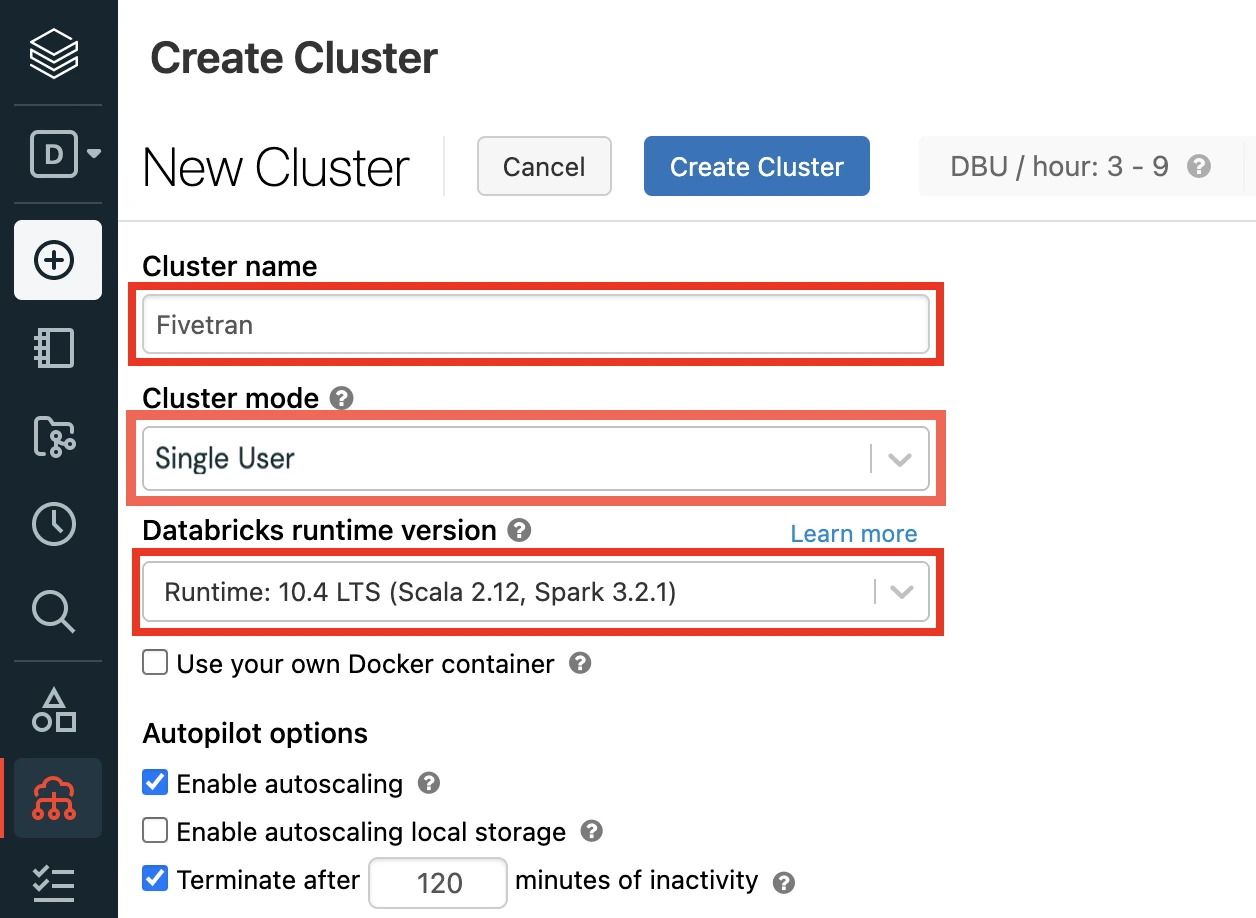
Select the Cluster mode.
Set the Databricks Runtime Version to 7.3 or later. (10.4 LTS Recommended)
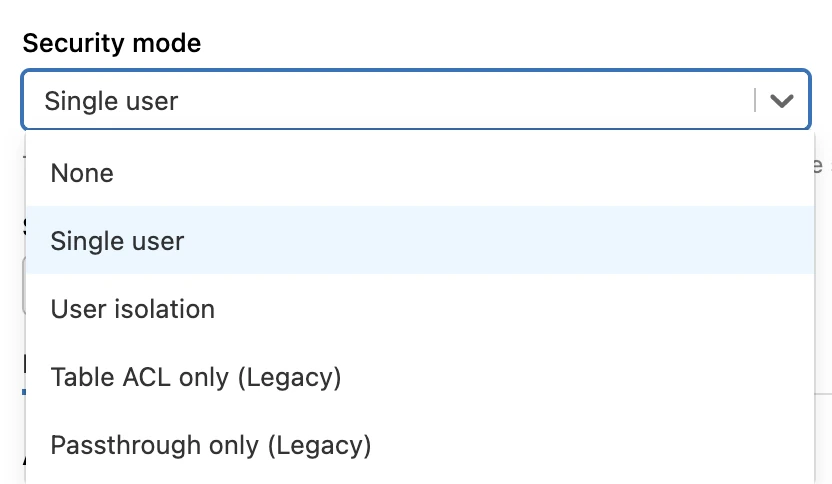
(Optional) If you are using the Unity Catalog feature, in the Advanced Options window, in the Security mode drop-down menu, select either Single user or User isolation.
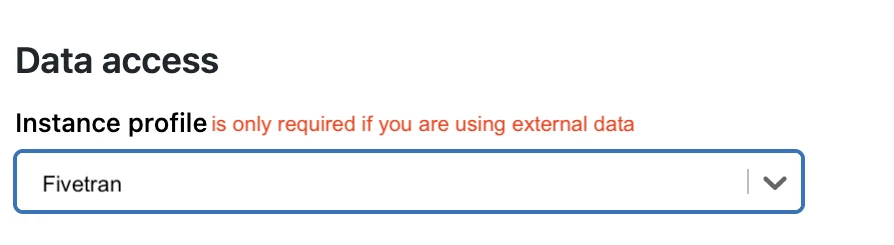
(Optional) If you are using an external data storage and have disabled the Unity Catalog feature, select the Instance profile you created in the Create instance profile step.
In the Advanced Options section, select Spark.
If you have set the Databricks Runtime Version to below 9.1, paste the following code in Spark config field:
spark.hadoop.fs.s3a.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem spark.hadoop.fs.s3n.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem spark.hadoop.fs.s3n.impl.disable.cache true spark.hadoop.fs.s3.impl.disable.cache true spark.hadoop.fs.s3a.impl.disable.cache true spark.hadoop.fs.s3.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem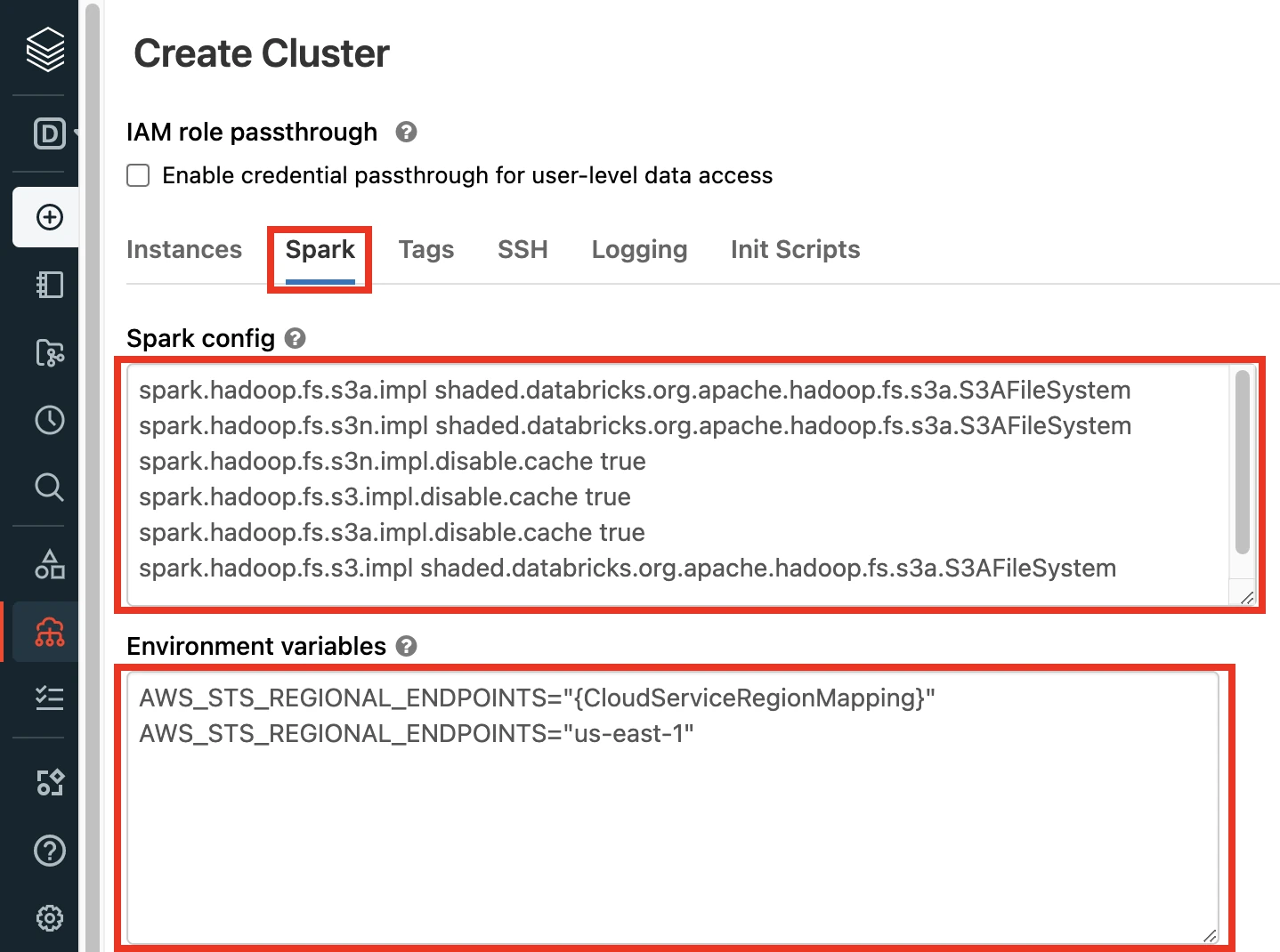
Click Create Cluster.
In the Advanced Options window, select JDBC/ODBC.
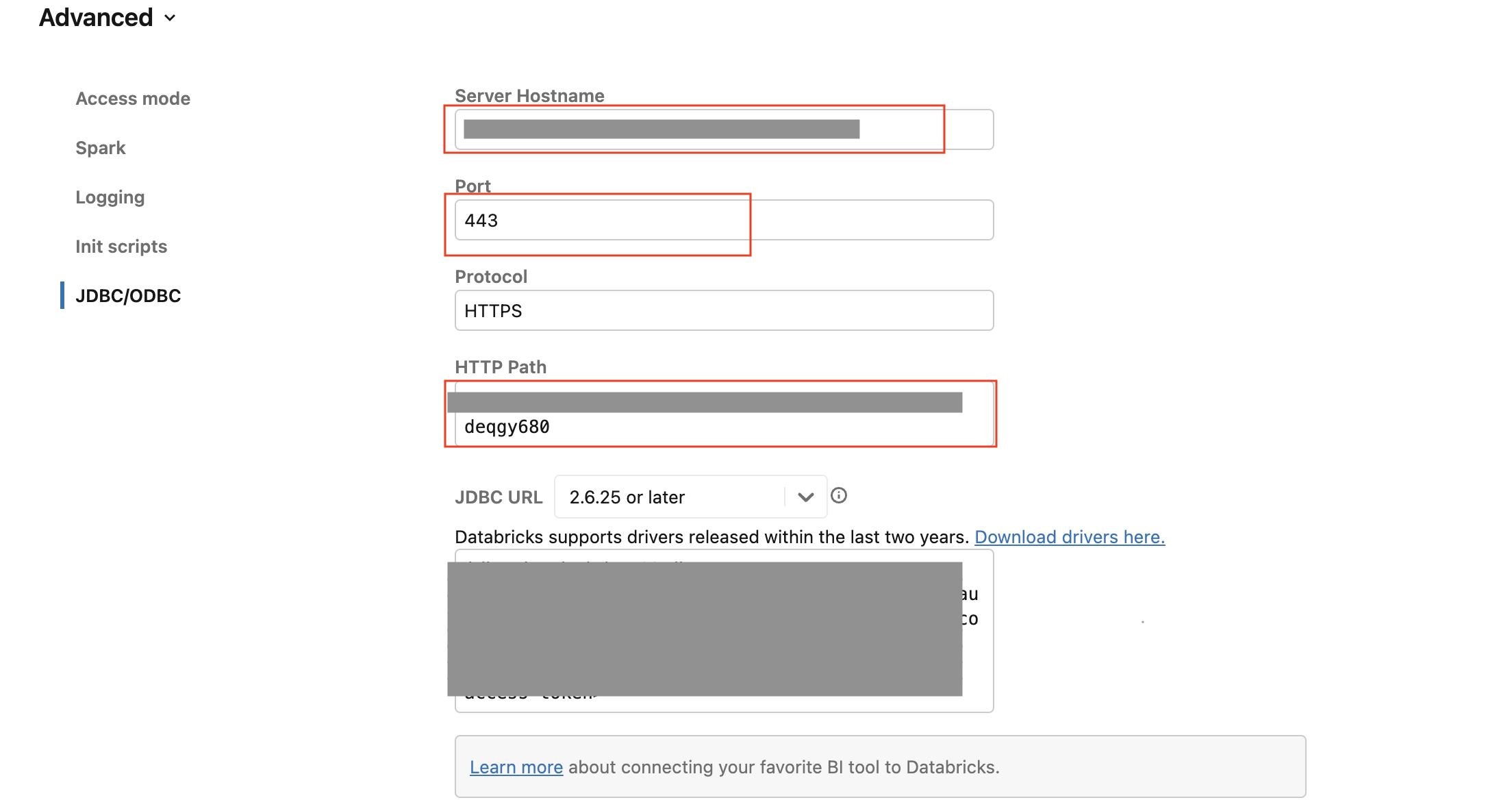
Make a note of the following values. You will need them to configure Fivetran.
- Server Hostname
- Port
- HTTP Path
For further instructions, skip to the Add external location and storage credentials step.
Databricks on Azure - Setup instructions
Learn how to set up your Databricks on Azure destination.
Expand for instructions
Databricks on Azure destinations with OAuth authentication don't support Transformations for dbt Core and Quickstart data models.
Choose your deployment model
Before setting up your destination, decide which deployment model best suits your organization's requirements. This destination supports both SaaS and Hybrid deployment models, offering flexibility to meet diverse compliance and data governance needs.
See our Deployment Models documentation to understand the use cases of each model and choose the model that aligns with your security and operational requirements.
You must have an Enterprise or Business Critical plan to use the Hybrid Deployment model.
(Optional) Configure Unity Catalog
Perform the following steps if you want to use the Unity Catalog feature or an external data storage.
You must set up Unity Catalog to sync unstructured files in Databricks. Without it, you won't be able to sync unstructured files.
Create a storage account
To create an Azure Blob Storage account, follow Microsoft's Create a storage account guide.
To create an Azure Data Lake Storage Gen2 storage account, follow Microsoft's Create a storage account to use with Azure Data Lake Storage Gen2 guide.
Create a container
To create a container in Azure Blob storage, follow Microsoft's Create a container guide.
To create a container in ADLS Gen2 storage, follow Microsoft's Create a container guide.
Configure a managed identity for Unity Catalog
Perform this step if you have enabled the Unity Catalog feature and want to access the metastore using a managed identity.
You can configure Unity Catalog (Preview) to use an Azure managed identity to access storage containers.
To configure a managed identity for Unity Catalog, follow Microsoft documentation.
Create a metastore and attach workspace
Perform this step if you have enabled the Unity Catalog feature.
To create a metastore and attach workspace, follow Microsoft's Create the metastore guide.
Choose connection method
Decide whether to connect Fivetran to your Databricks destination directly or using Azure Private Link.
Connect directly
This is the simplest connection method where Fivetran connects directly to your Databricks destination. This is the default connection method and you do not have to set up or configure anything to use it.
Connect using Azure Private Link
You must have a Business Critical plan to use Azure Private Link.
Azure Private Link allows VNet and Azure-hosted or on-premises services to communicate with one another without exposing traffic to the public internet. Learn more in Microsoft's Azure Private Link documentation.
Prerequisites
To set up Azure Private Link, you need:
- A Fivetran instance configured to run in Azure
- A Databricks destination in one of our supported regions
- An Azure Databricks workspace that is in your own virtual network (Vnet injection). Learn more in Azure's Create an Azure Databricks workspace in your own Virtual Network documentation.
Fivetran cannot connect Private Link to an Azure Databricks workspace that's spun using default deployments.
Configure Azure Private Link
Create or select an Azure Databricks workspace that was spun using the Vnet injection deployment method.
Send your ID and Workspace URL to your Fivetran account manager. Fivetran sets up the Azure Private Link connection on our side.
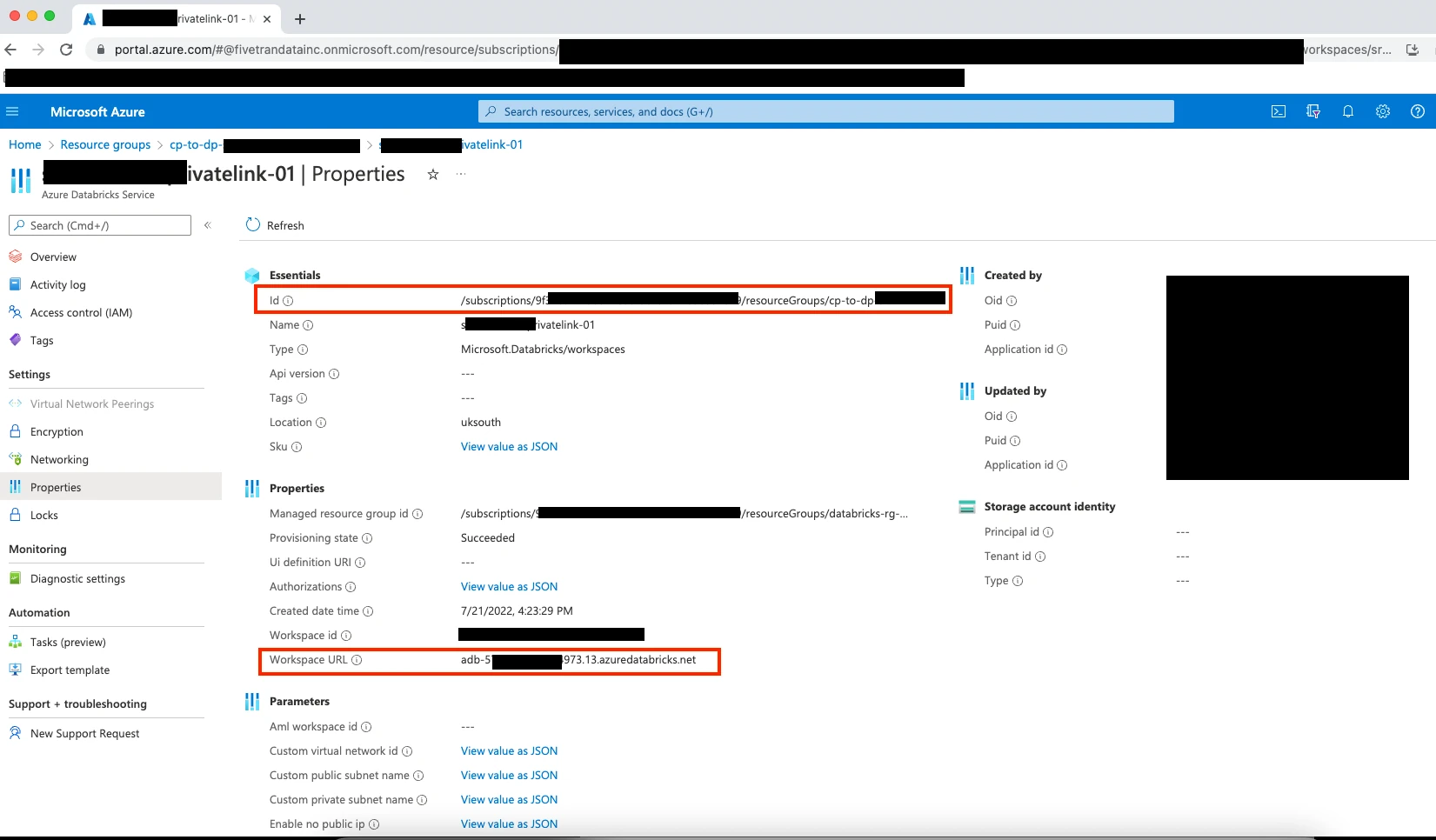
Once your account manager confirms our setup was successful, approve our endpoint connection request. Setup is now complete.
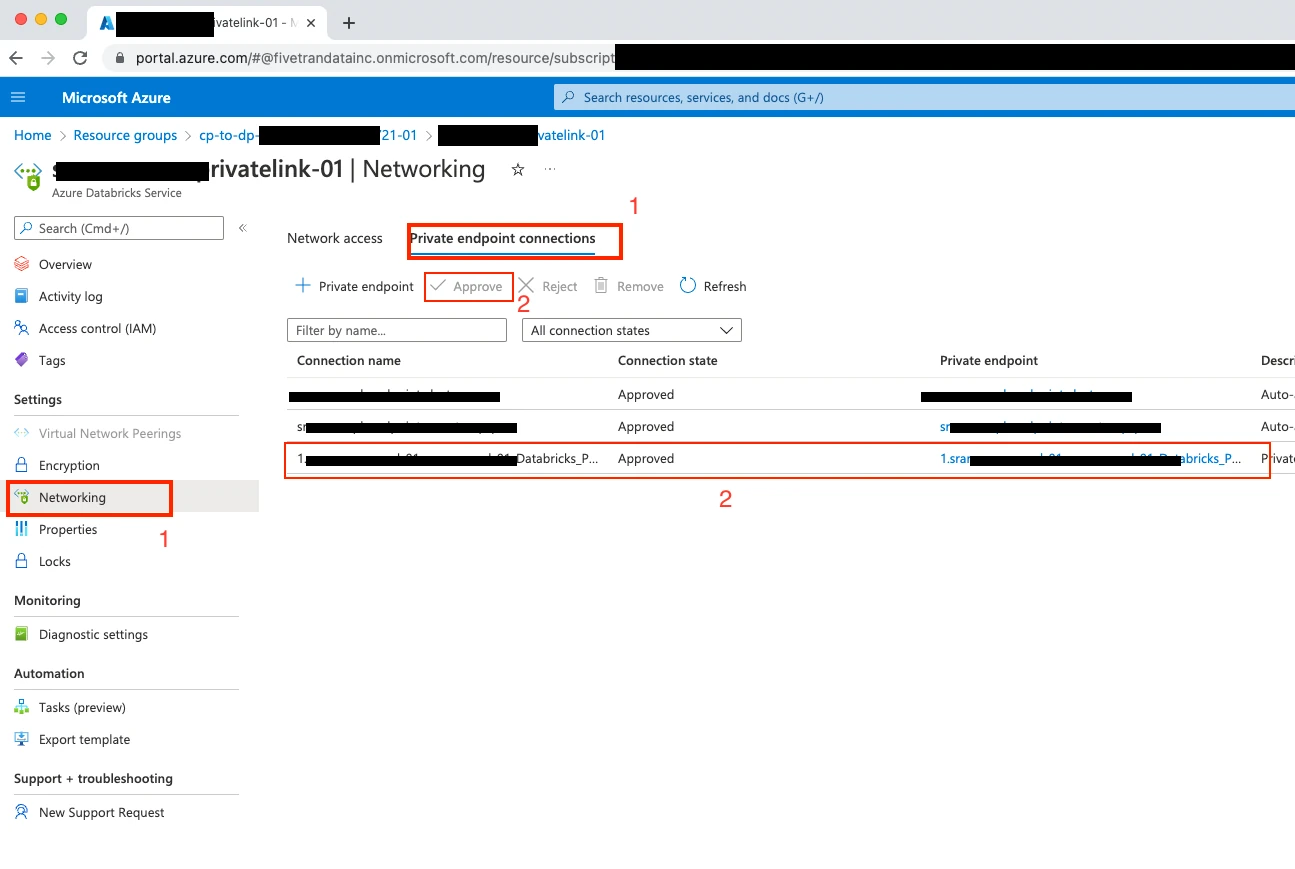
Connect Databricks cluster
If you want to set up a SQL warehouse, skip to the Connect SQL warehouse step.
Log in to your Databricks workspace.
In the navigation menu, select Compute and then click Create compute.

Enter a Compute name, and set the Databricks Runtime Version to 7.3 or later.
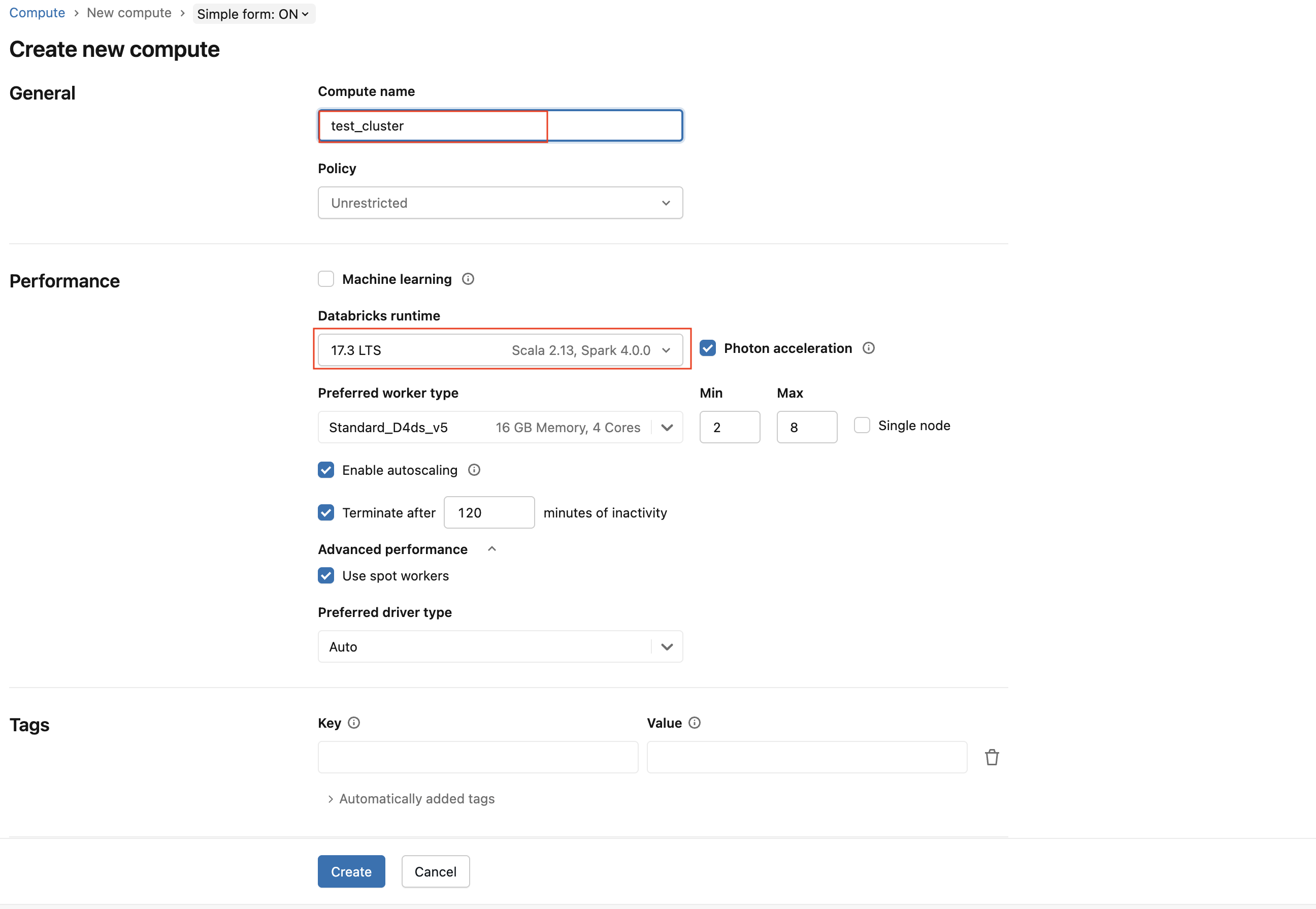
If you are using the Unity Catalog feature, expand Advanced Options and select Access mode.
In the Access mode section, select Manual and in the drop-down menu, select Dedicated (formerly Single user).
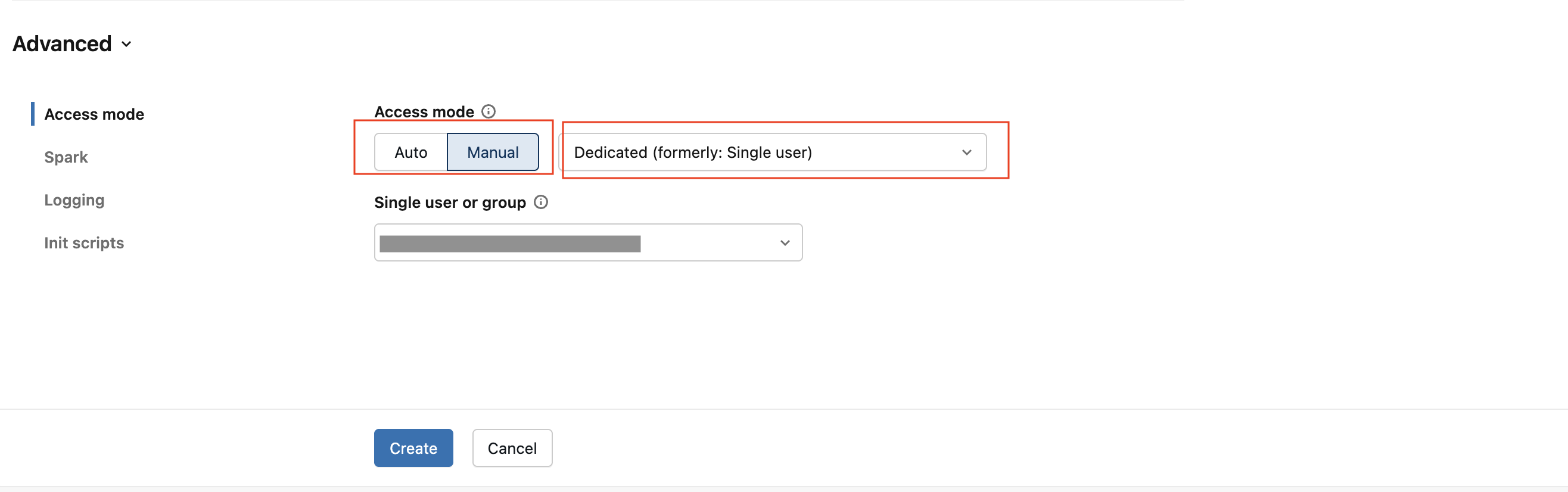
Click Create.
Once the cluster is created, in the Advanced tab, select JDBC/ODBC.
Make a note of the following values. You will need them to configure Fivetran.
- Server Hostname
- Port
- HTTP Path
For further instructions, skip to the Setup external location step.
Connect SQL warehouse
Log in to your Databricks workspace.
In the Databricks console, go to SQL > Create > SQL Warehouse.
In the New SQL warehouse window, enter a Name for your warehouse.
Choose your Cluster Size and configure the other warehouse options.
Fivetran recommends starting with the 2X-Small cluster size and scaling up as your workload demands.
Choose your warehouse type:
- Serverless
- Pro
- Classic
The Serverless option appears only if serverless is enabled in your account. For more information about warehouse types, see Databricks' documentation.
(Optional) If you are using the Unity Catalog feature, in the Advanced options section, enable the Unity Catalog toggle and set the Channel to Preview.
Click Create.
Go to the Connection details tab.
Make a note of the following values. You will need them to configure Fivetran.
- Server Hostname
- Port
- HTTP Path
Configure external staging for Hybrid Deployment
Skip to the next step if you want to use Fivetran's cloud environment to sync your data. Perform this step only if you want to use the Hybrid Deployment model for your data pipeline.
Configure one of the following external storages to stage your data before writing it to your destination:
Amazon S3 bucket (recommended)
Create Amazon S3 bucket
Create an S3 bucket by following the instructions in AWS documentation.
Fivetran stages data in the S3 bucket using server-side encryption with customer-provided keys (SSE-C). By default, buckets created in the AWS console block SSE-C uploads.
In the bucket settings, go to Properties > Default encryption and make sure SSE-C (server-side encryption with customer-provided keys) is not selected under Blocked encryption types.
If the bucket blocks SSE-C uploads, the Validate Permissions setup test fails with the following error, even when the IAM credentials are valid:
Invalid storage container credentials, please check the key and secret provided for LDP
Create IAM policy for S3 bucket
Log in to the Amazon IAM console.
Go to Policies, and then click Create policy.
Go to the JSON tab.
Copy the following policy and paste it in the JSON editor.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:DeleteObjectTagging", "s3:ReplicateObject", "s3:PutObject", "s3:GetObjectAcl", "s3:GetObject", "s3:DeleteObjectVersion", "s3:ListBucket", "s3:PutObjectTagging", "s3:DeleteObject", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::{your-bucket-name}/*", "arn:aws:s3:::{your-bucket-name}" ] } ] }In the policy, replace
{your-bucket-name}with the name of your S3 bucket.Click Next.
Enter a Policy name.
Click Create policy.
(Optional) Configure IAM role authentication
- Perform this step only if you want us to use AWS Identity and Access Management (IAM) to authenticate the requests in your S3 bucket. Skip to the next step if you want to use IAM user credentials for authentication.
- To authenticate using IAM, your Hybrid Deployment Agent must run on an EC2 instance in the account associated with your S3 bucket.
In the Amazon IAM console, go to Roles, and then click Create role.
Select AWS service.
In Service or use case drop-down menu, select EC2.
Click Next.
Select the checkbox for the IAM policy you created for your S3 bucket.
Click Next.
Enter the Role name and click Create role.
In the Amazon IAM console, go to the EC2 service.
Go to Instances, and then select the EC2 instance hosting your Hybrid Deployment Agent.
In the top right corner, click Actions and go to Security > Modify IAM role.
In the IAM role drop-down menu, select the new IAM role you created and click Update IAM role.
(Optional) Configure IAM user authentication
Perform this step only if you want us to use IAM user credentials to authenticate the requests in your S3 bucket.
In the Amazon IAM console, go to Users, and then click Create user.
Enter a User name, and then click Next.
Select Attach policies directly.
Select the checkbox next to the policy you created in the Create IAM policy for S3 bucket step, and then click Next.
In the Review and create page, click Create user.
In the Users page, select the user you created.
Click Create access key.
Select Application running outside AWS, and then click Next.
Click Create access key.
Click Download .csv file to download the Access key ID and Secret access key to your local drive. You will need them to configure Fivetran.
Azure Blob storage container
Create Azure storage account
Create an Azure storage account by following the instructions in Azure documentation. When creating the account, make sure you do the following:
In the Advanced tab, select the Require secure transfer for REST API operations and Enable storage account key access checkboxes.
In the Permitted scope for copy operations drop-down menu, select From any storage account.
In the Networking tab, select one of the following Network access options:
- If your Databricks destination is not hosted on Azure or if your storage container and destination are in different regions, select Enable public access from all networks.
- If your Databricks destination is hosted on Azure and if it is in the same region as your storage container, select Enable public access from selected virtual networks and IP addresses.
Ensure the virtual network or subnet where your Databricks workspace or cluster resides is included in the allowed list for public access on the Azure storage account.
In the Encryption tab, choose Microsoft-managed keys (MMK) as the Encryption type.
Find storage account name and access key
Log in to the Azure portal.
Go to your storage account.
On the navigation menu, click Access keys under Security + networking.
Make a note of the Storage account name and Key. You will need them to configure Fivetran.
As a security best practice, do not save your access key and account name anywhere in plain text that is accessible to others.
(Optional) Configure service principal for authentication
Perform the steps in this section only if you want to configure service principal (client credentials) authentication for your Azure Blob storage container. Skip to the next step if you want to use your storage account credentials for authentication.
Register application and add service principal
On the navigation menu, select Microsoft Entra ID (formerly Azure Active Directory).
Go to App registrations and click + New registration.
Enter a Name for the application.
In the Supported account types section, select Accounts in this organizational directory only and click Register.
Make a note of the Application (client) ID and Directory (tenant) ID. You will need them to configure Fivetran.
Create client secret
Select the application you registered.
On the navigation menu, go to Certificates & secrets and click + New client secret.
Enter a Description for your client secret.
In the Expires drop-down menu, select an expiry period for the client secret.
Click Add.
Make a note of the client secret. You will need it to configure Fivetran.
Assign role to storage account
You must assign the Storage Blob Delegator role at the storage account level because the service principal issues a User Delegation SAS token. We need this token to access the container, and although the SAS is scoped to a specific container, it can generate the token only when the role assignment exists at the storage account level.
Go to the storage account you created.
On the navigation menu, click Access Control (IAM).
Click Add and select Add role assignment.
In the Role tab, select Storage Blob Delegator and click Next.
In the Members tab, select User, group, or service principal.
Click + Select members.
In the Select members pane, select the service principal you added and then click Select.
Click Review + assign.
Assign role to container
Go to your ADLS container and select Access Control (IAM).
Click Add and then select Add role assignments.
In the Role tab, select Storage Blob Data Contributor and click Next.
In the Member tab, select User, group, or service principal.
Click + Select members.
In the Select members pane, select the service principal you added and then click Select.
Click Review + assign.
(Optional) Setup external location
With Unity Catalog
- To add a storage credential, follow Microsoft's Manage storage credential guide.
- To add an external location, follow Microsoft's Manage external location guide.
Fivetran uses the external location and storage credentials to write data on your cloud tenant.
With Hive metastore
Follow any one of the following Databricks' guides to provide us the permission to write data in Access Azure Data Lake Storage Gen2 or Azure Blob:
- Access Azure Data Lake Storage Gen2 or Blob Storage using OAuth 2.0 with an Azure service principal
- Access Azure Data Lake Storage Gen2 or Blob Storage using a SAS token
- Access Azure Data Lake Storage Gen2 or Blob Storage using the account key
Instead of executing the Python code provided in the above links, you can also assign the spark configs to the standard Databricks cluster you created in the Connect Databricks cluster step, or the SQL warehouse you created in the Connect SQL warehouse step.
Choose authentication type
You can use one of the following authentication types for Fivetran to connect to Databricks:
Databricks personal access token authentication: Supports all Databricks destinations
OAuth machine-to-machine (M2M) authentication: Supports the Databricks destinations that are not connected to Fivetran using AWS PrivateLink or Azure Private Link
Configure Databricks personal access token authentication
To use the Databricks personal access token authentication type, create a personal access token by following the instructions in Databricks' personal access token authentication documentation.
If you do not use Unity Catalog, the user or service principal you want to use to create your access token must have the following privileges on the schema:
- SELECT
- MODIFY
READ_METADATA
USAGE
CREATE
If you use Unity Catalog, the user or service principal you want to use to create your access token must have the following privileges on the catalog:
- CREATE SCHEMA
- CREATE TABLE
MODIFY
SELECT
USE CATALOG
USE SCHEMA
If you use Unity Catalog to create external tables in a Unity Catalog-managed external location, the user or service principal you want to use to create your access token must have the following privileges:
- On the external location: - CREATE EXTERNAL TABLE
READ FILES
WRITE FILES
On the storage credentials: - CREATE EXTERNAL TABLE
READ FILES
WRITE FILES
When you grant a privilege on the catalog, it is automatically granted to all current and future schemas in the catalog. Similarly, the privileges that you grant on a schema are inherited by all current and future tables in the schema.
Configure OAuth machine-to-machine (M2M) authentication
To use the OAuth machine-to-machine (M2M) authentication type, create your OAuth Client ID and Secret by following the instructions in Databricks' OAuth machine-to-machine (M2M) authentication documentation.
You cannot use this authentication type if you connect your destination to Fivetran using AWS PrivateLink or Azure Private Link.
Complete Fivetran configuration
Log in to your Fivetran account.
Go to the Destinations page and click Add destination.
Enter a Destination name of your choice and then click Add.
Select Databricks as the destination type.
(Enterprise and Business Critical accounts only) Select the deployment model of your choice:
- SaaS Deployment
- Hybrid Deployment
If you selected Hybrid Deployment, click Select Hybrid Deployment Agent and do one of the following:
- To use an existing agent, select the agent you want to use, and click Use Agent.
- To create a new agent, click Create new agent and follow the setup instructions specific to your container platform.
(Hybrid Deployment only) Choose the container service (external storage) you configured to stage your data.
If you chose AWS S3, in the Authentication type drop-down menu, select the authentication type you configured for your S3 bucket.
If you selected IAM_ROLE, enter the name and region of your S3 bucket.
If you selected IAM_USER, enter the following details of your S3 bucket:
- Name
- Region
- AWS access key ID
- AWS secret access key
If you chose Azure Blob Storage, in the Authentication type drop-down menu, select the authentication type you configured for your Azure Blob Storage container.
If you selected Storage Account Key, enter the storage account name and storage account key you found.
If you selected Client Credentials, enter the following details:
- Storage account name
- Client ID and client secret of your service principal
- Tenant ID of your service principal
(Not applicable to Hybrid Deployment) Choose your Connection Method:
- Connect directly
- Connect via Private Link
The Connect via Private Link option is only available for Business Critical accounts.
(Optional) Enter the Catalog name.
Enter the Server Hostname.
If we auto-detect your Databricks Deployment Cloud, the Databricks Deployment Cloud field won't be visible in the setup form.
Enter the Port number.
Enter the HTTP Path.
Specify the authentication details for your destination.
- If you selected Connect directly as the connection method, in the Authentication Type drop-down menu, select the authentication type you want Fivetran to connect to your destination. If you selected PERSONAL ACCESS TOKEN in the drop-down menu, enter the Personal Access Token you created. If you selected OAUTH 2.0 in the drop-down menu, enter the OAuth 2.0 Client ID and OAuth 2.0 Secret you created.
- If you selected Connect via PrivateLink as the connection method, enter the Personal Access Token you created.
(Optional) Choose the Databricks Deployment Cloud based on your infrastructure.
(Optional) Set the Create Delta tables in an external location toggle to ON to create Delta tables as external tables. You can choose either of the following options:
You cannot edit the toggle field and external volume location path after you save the setup form.
- Enter the External Location you want to use. We will create the Delta tables in the
{externallocation}/{schema}/{table}path - Do not specify the external location. We will create the external Delta tables in the
/{schema}/{table}path. Depending on the Unity Catalog settings:- If Unity Catalog is disabled - we will use the default Databricks File System location registered with the cluster
- If Unity Catalog is enabled - we will use the root storage location in the Azure Data Lake Storage Gen2 container provided while creating a metastore
- Enter the External Location you want to use. We will create the Delta tables in the
Private Preview (Optional) Set the Create volumes in an external location toggle to ON to create volumes in external location.
- Databricks Volume feature is only supported on Unity catalog.
- You cannot edit the toggle and external volume location path after you save the setup form.
- The user or service principal must have the CREATE VOLUME privilege granted at the schema level to create volumes. Databricks recommends granting this privilege at the schema level. You can also grant this privilege on a catalog to allow the user to create volumes in any existing or future schema in the catalog.
- If your Azure Blob Storage account has a firewall or virtual network restrictions enabled, Databricks may be unable to access it for unstructured file uploads. If you encounter access errors, create a Fivetran support ticket to configure a private networking connection between Fivetran and your Azure Blob Storage account.
- Enter the External Volume Location you want to use. Specify your external volume location to sync unstructured files in an external location. We will sync the unstructured files in the
{External Volume Location from UI}/Volumes/{schema}/{table}path.
Be sure not to use "volume", "volumes", or "tables" as keywords for catalog, schema, and table names when syncing unstructured files.
(Optional) Set the Disable VACUUM operations toggle to ON to stop Fivetran from running VACUUM operations on your Databricks tables. By default, the toggle is set to OFF, and Fivetran automatically runs VACUUM operations during scheduled table cleanup to optimize storage.
- Disabling the VACUUM operations may increase storage usage over time as old file versions accumulate.
- You can update this setting anytime after the initial setup.
Choose the Data processing location. Depending on the plan you are on and your selected cloud service provider, you may also need to choose a Cloud service provider and cloud region as described in our Destinations documentation.
Choose your Time zone.
(Optional for Business Critical accounts and SaaS Deployment) To enable regional failover, set the Use Failover toggle to ON, and then select your Failover Location and Failover Region. Make a note of the IP addresses of the secondary region and safelist these addresses in your firewall.
Click Save & Test.
Fivetran tests and validates the Databricks connection. On successful completion of the setup tests, you can sync your data using Fivetran connectors to the Databricks destination.
In addition, Fivetran automatically configures a Fivetran Platform connection to transfer the connection logs and account metadata to a schema in this destination. The Fivetran Platform Connector enables you to monitor your connections, track your usage, and audit changes. The Fivetran Platform connection sends all these details at the destination level.
If you are an Account Administrator, you can manually add the Fivetran Platform connection on an account level so that it syncs all the metadata and logs for all the destinations in your account to a single destination. If an account-level Fivetran Platform connection is already configured in a destination in your Fivetran account, then we don't add destination-level Fivetran Platform connections to the new destinations you create.
Databricks on GCP - Setup instructions
Learn how to set up your Databricks on GCP destination.
Expand for instructions
Choose your deployment model
Before setting up your destination, decide which deployment model best suits your organization's requirements. This destination supports both SaaS and Hybrid deployment models, offering flexibility to meet diverse compliance and data governance needs.
See our Deployment Models documentation to understand the use cases of each model and choose the model that aligns with your security and operational requirements.
You must have an Enterprise or Business Critical plan to use the Hybrid Deployment model.
Choose a catalog
If you don't use Unity Catalog, skip to the Connect SQL warehouse step. Fivetran will create schemas in the default catalog, hive_metastore.
If you use Unity Catalog, you need to decide which catalog to use with Fivetran. For example, you could create a catalog called fivetran and organize tables from different connections in it in separate schemas, like fivetran.salesforce or fivetran.mixpanel. If you need to set up Unity Catalog, follow Databricks' Get started using Unity Catalog guide.
Log in to your Databricks workspace.
Click Data in the Databricks console.
Choose a catalog in the Data Explorer.
You must set up Unity Catalog to sync unstructured files in Databricks. Without it, you won't be able to sync unstructured files.
Connect Databricks cluster
If you want to set up a SQL warehouse, skip to the Connect SQL warehouse step.
Log in to your Databricks workspace.
In the Databricks console, go to Data Science & Engineering > Create > Cluster.
Enter a Cluster name of your choice.
Select the Cluster mode.
For more information about cluster modes, see Databricks' documentation.
Set the Databricks Runtime Version to 7.3 or later. (10.4 LTS Recommended)
(Optional) If you are using the Unity Catalog feature, in the Advanced Options window, in the Security mode drop-down menu, select either Single user or User isolation.
Click Create Cluster.
In the Advanced Options window, select JDBC/ODBC.
Make a note of the following values. You will need them to configure Fivetran.
- Server Hostname
- Port
- HTTP Path
For further instructions, skip to the Setup external location step.
Connect SQL warehouse
Log in to your Databricks workspace.
In the Databricks console, go to SQL > Create > SQL Warehouse.
In the New SQL warehouse window, enter a Name for your warehouse.
Choose your Cluster Size and configure the other warehouse options.
Fivetran recommends starting with the 2X-Small cluster size and scaling up as your workload demands.
Choose your warehouse type:
- Serverless
- Pro
- Classic
The Serverless option appears only if serverless is enabled in your account. For more information about warehouse types, see Databricks' documentation.
(Optional) If you are using the Unity Catalog feature, in the Advanced options section, enable the Unity Catalog toggle and set the Channel to Preview.
Click Create.
Go to the Connection details tab.
Make a note of the following values. You will need them to configure Fivetran.
- Server Hostname
- Port
- HTTP Path
Configure external staging for Hybrid Deployment
Skip to the next step if you want to use Fivetran's cloud environment to sync your data. Perform this step only if you want to use the Hybrid Deployment model for your data pipeline.
Configure one of the following external storages to stage your data before writing it to your destination:
Amazon S3 bucket (recommended)
Create Amazon S3 bucket
Create an S3 bucket by following the instructions in AWS documentation.
Fivetran stages data in the S3 bucket using server-side encryption with customer-provided keys (SSE-C). By default, buckets created in the AWS console block SSE-C uploads.
In the bucket settings, go to Properties > Default encryption and make sure SSE-C (server-side encryption with customer-provided keys) is not selected under Blocked encryption types.
If the bucket blocks SSE-C uploads, the Validate Permissions setup test fails with the following error, even when the IAM credentials are valid:
Invalid storage container credentials, please check the key and secret provided for LDP
Create IAM policy for S3 bucket
Log in to the Amazon IAM console.
Go to Policies, and then click Create policy.
Go to the JSON tab.
Copy the following policy and paste it in the JSON editor.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:DeleteObjectTagging", "s3:ReplicateObject", "s3:PutObject", "s3:GetObjectAcl", "s3:GetObject", "s3:DeleteObjectVersion", "s3:ListBucket", "s3:PutObjectTagging", "s3:DeleteObject", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::{your-bucket-name}/*", "arn:aws:s3:::{your-bucket-name}" ] } ] }In the policy, replace
{your-bucket-name}with the name of your S3 bucket.Click Next.
Enter a Policy name.
Click Create policy.
(Optional) Configure IAM role authentication
- Perform this step only if you want us to use AWS Identity and Access Management (IAM) to authenticate the requests in your S3 bucket. Skip to the next step if you want to use IAM user credentials for authentication.
- To authenticate using IAM, your Hybrid Deployment Agent must run on an EC2 instance in the account associated with your S3 bucket.
In the Amazon IAM console, go to Roles, and then click Create role.
Select AWS service.
In Service or use case drop-down menu, select EC2.
Click Next.
Select the checkbox for the IAM policy you created for your S3 bucket.
Click Next.
Enter the Role name and click Create role.
In the Amazon IAM console, go to the EC2 service.
Go to Instances, and then select the EC2 instance hosting your Hybrid Deployment Agent.
In the top right corner, click Actions and go to Security > Modify IAM role.
In the IAM role drop-down menu, select the new IAM role you created and click Update IAM role.
(Optional) Configure IAM user authentication
Perform this step only if you want us to use IAM user credentials to authenticate the requests in your S3 bucket.
In the Amazon IAM console, go to Users, and then click Create user.
Enter a User name, and then click Next.
Select Attach policies directly.
Select the checkbox next to the policy you created in the Create IAM policy for S3 bucket step, and then click Next.
In the Review and create page, click Create user.
In the Users page, select the user you created.
Click Create access key.
Select Application running outside AWS, and then click Next.
Click Create access key.
Click Download .csv file to download the Access key ID and Secret access key to your local drive. You will need them to configure Fivetran.
Azure Blob storage container
Create Azure storage account
Create an Azure storage account by following the instructions in Azure documentation. When creating the account, make sure you do the following:
In the Advanced tab, select the Require secure transfer for REST API operations and Enable storage account key access checkboxes.
In the Permitted scope for copy operations drop-down menu, select From any storage account.
In the Networking tab, select one of the following Network access options:
- If your Databricks destination is not hosted on Azure or if your storage container and destination are in different regions, select Enable public access from all networks.
- If your Databricks destination is hosted on Azure and if it is in the same region as your storage container, select Enable public access from selected virtual networks and IP addresses.
Ensure the virtual network or subnet where your Databricks workspace or cluster resides is included in the allowed list for public access on the Azure storage account.
In the Encryption tab, choose Microsoft-managed keys (MMK) as the Encryption type.
Find storage account name and access key
Log in to the Azure portal.
Go to your storage account.
On the navigation menu, click Access keys under Security + networking.
Make a note of the Storage account name and Key. You will need them to configure Fivetran.
As a security best practice, do not save your access key and account name anywhere in plain text that is accessible to others.
(Optional) Configure service principal for authentication
Perform the steps in this section only if you want to configure service principal (client credentials) authentication for your Azure Blob storage container. Skip to the next step if you want to use your storage account credentials for authentication.
Register application and add service principal
On the navigation menu, select Microsoft Entra ID (formerly Azure Active Directory).
Go to App registrations and click + New registration.
Enter a Name for the application.
In the Supported account types section, select Accounts in this organizational directory only and click Register.
Make a note of the Application (client) ID and Directory (tenant) ID. You will need them to configure Fivetran.
Create client secret
Select the application you registered.
On the navigation menu, go to Certificates & secrets and click + New client secret.
Enter a Description for your client secret.
In the Expires drop-down menu, select an expiry period for the client secret.
Click Add.
Make a note of the client secret. You will need it to configure Fivetran.
Assign role to storage account
You must assign the Storage Blob Delegator role at the storage account level because the service principal issues a User Delegation SAS token. We need this token to access the container, and although the SAS is scoped to a specific container, it can generate the token only when the role assignment exists at the storage account level.
Go to the storage account you created.
On the navigation menu, click Access Control (IAM).
Click Add and select Add role assignment.
In the Role tab, select Storage Blob Delegator and click Next.
In the Members tab, select User, group, or service principal.
Click + Select members.
In the Select members pane, select the service principal you added and then click Select.
Click Review + assign.
Assign role to container
Go to your ADLS container and select Access Control (IAM).
Click Add and then select Add role assignments.
In the Role tab, select Storage Blob Data Contributor and click Next.
In the Member tab, select User, group, or service principal.
Click + Select members.
In the Select members pane, select the service principal you added and then click Select.
Click Review + assign.
(Optional) Setup external location
With Unity Catalog
- To add a storage credential, follow Microsoft's Manage storage credential guide.
- To add an external location, follow Microsoft's Manage external location guide.
Fivetran uses the external location and storage credentials to write data on your cloud tenant.
With Hive metastore
Follow Databricks' documentation to provide us the permissions necessary to write data to Google Cloud Storage.
Configure authentication type
Fivetran uses Databricks personal access token authentication to connect to Databricks destinations hosted on GCP.
To use this authentication type, create a personal access token by following the instructions in Databricks' personal access token authentication documentation.
If you do not use Unity Catalog, the user or service principal you want to use to create your access token must have the following privileges on the schema:
- SELECT
- MODIFY
- READ_METADATA
USAGE
CREATE
If you use Unity Catalog, the user or service principal you want to use to create your access token must have the following privileges on the catalog:
- CREATE SCHEMA
- CREATE TABLE
- MODIFY
SELECT
USE CATALOG
USE SCHEMA
If you use Unity Catalog to create external tables in a Unity Catalog-managed external location, the user or service principal you want to use to create your access token must have the following privileges:
On the external location:
CREATE EXTERNAL TABLE
READ FILES
WRITE FILES
On the storage credentials: - CREATE EXTERNAL TABLE
READ FILES
WRITE FILES
When you grant a privilege on the catalog, it is automatically granted to all current and future schemas in the catalog. Similarly, the privileges that you grant on a schema are inherited by all current and future tables in the schema.
Complete Fivetran configuration
Log in to your Fivetran account.
Go to the Destinations page and click Add destination.
Enter a Destination name of your choice and then click Add.
Select Databricks as the destination type.
(Enterprise and Business Critical accounts only) Select the deployment model of your choice:
- SaaS Deployment
- Hybrid Deployment
If you selected Hybrid Deployment, click Select Hybrid Deployment Agent and do one of the following:
- To use an existing agent, select the agent you want to use, and click Use Agent.
- To create a new agent, click Create new agent and follow the setup instructions specific to your container platform.
(Hybrid Deployment only) Choose the container service (external storage) you configured to stage your data.
If you chose AWS S3, in the Authentication type drop-down menu, select the authentication type you configured for your S3 bucket.
If you selected IAM_ROLE, enter the name and region of your S3 bucket.
If you selected IAM_USER, enter the following details of your S3 bucket:
- Name
- Region
- AWS access key ID
- AWS secret access key
If you chose Azure Blob Storage, in the Authentication type drop-down menu, select the authentication type you configured for your Azure Blob Storage container.
If you selected Storage Account Key, enter the storage account name and storage account key you found.
If you selected Client Credentials, enter the following details:
- Storage account name
- Client ID and client secret of your service principal
- Tenant ID of your service principal
(Optional) Enter the Catalog name.
Enter the Server Hostname.
Enter the Port number.
Enter the HTTP Path.
Enter the Personal Access Token you created.
(Optional) Choose the Databricks Deployment Cloud based on your infrastructure.
If we auto-detect your Databricks Deployment Cloud, the Databricks Deployment Cloud field won't be visible in the setup form. If you select Connect via Private Link as the connection method, the Databricks Deployment Cloud field will be populated automatically after you create the destination.
(Optional) Set the Create Delta tables in an external location toggle to ON to create Delta tables as external tables. You can choose either of the following options:
You cannot edit the toggle and external location path after you save the setup form.
- Enter the External Location you want to use. We will create the Delta tables in the
{externallocation}/{schema}/{table}path - Do not specify the external location. We will create the external Delta tables in the
/{schema}/{table}path. Depending on the Unity Catalog settings:- If Unity Catalog is disabled - we will use the default Databricks File System location registered with the cluster
- If Unity Catalog is enabled - we will use the root storage location in the Google Cloud Storage bucket provided while creating a metastore
- Enter the External Location you want to use. We will create the Delta tables in the
Private Preview (Optional) Set the Create volumes in an external location toggle to ON to create volumes in external location.
- Databricks Volume feature is only supported on Unity catalog.
- You cannot edit the toggle and external volume location path after you save the setup form.
- The user or service principal must have the CREATE VOLUME privilege granted at the schema level to create volumes. Databricks recommends granting this privilege at the schema level. You can also grant this privilege on a catalog to allow the user to create volumes in any existing or future schema in the catalog.
- Enter the External Volume Location you want to use. Specify your external volume location to sync unstructured files in an external location. We will sync the unstructured files in the
{External Volume Location from UI}/Volumes/{schema}/{table}path.
Be sure not to use "volume", "volumes", or "tables" as keywords for catalog, schema, and table names when syncing unstructured files.
Choose the Data processing location. Depending on the plan you are on and your selected cloud service provider, you may also need to choose a Cloud service provider and cloud region as described in our Destinations documentation.
Choose your Time zone.
(Optional for Business Critical accounts and SaaS Deployment) To enable regional failover, set the Use Failover toggle to ON, and then select your Failover Location and Failover Region. Make a note of the IP addresses of the secondary region and safelist these addresses in your firewall.
Click Save & Test.
Fivetran tests and validates the Databricks connection. On successful completion of the setup tests, you can sync your data using Fivetran connectors to the Databricks destination.
In addition, Fivetran automatically configures a Fivetran Platform connection to transfer the connection logs and account metadata to a schema in this destination. The Fivetran Platform Connector enables you to monitor your connections, track your usage, and audit changes. The Fivetran Platform connection sends all these details at the destination level.
If you are an Account Administrator, you can manually add the Fivetran Platform connection on an account level so that it syncs all the metadata and logs for all the destinations in your account to a single destination. If an account-level Fivetran Platform connection is already configured in a destination in your Fivetran account, then we don't add destination-level Fivetran Platform connections to the new destinations you create.
Setup tests
Fivetran performs the following Databricks connection tests:
The Connection test checks if we can connect to the Databricks cluster through Java Database Connectivity (JDBC) using the credentials you provided in the setup form.
The Check Version Compatibility test verifies the Databricks cluster version's compatibility with Fivetran.
The Check Cluster Configuration test validates the Databricks cluster's environment variables and the spark configuration for standard clusters with DBR version < 9.1.
The Validate Permissions test checks if we have the necessary READ/WRITE permissions to
CREATE,ALTER, orDROPtables in the database. The test also checks if we have the permissions to copy data from Fivetran's external AWS S3 staging bucket.The tests may take a couple of minutes to finish running.