April 2018
All destinations
When the source specifies a DECIMAL precision or scale that the destination can't support, we now convert that column to DOUBLE type.
Logs
Log events
We have renamed the MessageEvent event to InfoEvent.
We have added two new log events:
json_value_too_longskip_column
For more information, see our Logs documentation.
Logs support
We have added support for logs for the following connectors:
- Braintree
- Apple App Store (formerly iTunes Connect)
- Kantata
New dashboard design
We have updated our dashboard design:
New connectors
AWS Lambda
AWS Lambda is a serverless computing platform that runs code in response to events and automatically manages the compute resources required by that code.
Read our AWS Lambda documentation.
Schema changes
GitHub
In the REQUESTED_REVIEWER_HISTORY table, the pull_request_id column now has a foreign key relationship to the PULL_REQUEST table.
In the ISSUE_MILESTONE_HISTORY table, the milestone_id field is now null for milestones that no longer exist.
HubSpot
We have added the following new columns to the tables below:
| TABLE | COLUMN |
|---|---|
ENGAGEMENT_META_EMAIL | post_send_status |
ENGAGEMENT_EMAIL | recipient_drop_reasons |
Marketo
We have added two new tables, EMAIL and API_USAGE.
Shopify
We have added the following new tables:
APPLIED_DISCOUNTCHECKOUTCHECKOUT_DISCOUNT_CODECHECKOUT_LINECHECKOUT_SHIPPING_LINECHECKOUT_TAX_LINEAPPLIED_GIFT_CARD
Improvements
Apple App Store
You can now view the list of your tables that are available for sync in your Fivetran dashboard.
BigQuery
We stage incoming BigQuery data in a special schema, which is configured to automatically delete its contents after seven days. For users with large data volumes, the storage cost for these tables for seven days can be significant, so we now drop these tables immediately. Note that if there are errors during the loading process, tables may still occasionally take seven days to be dropped.
We have renamed the staging schema from _fivetran_staging to fivetran_schema. Schemas whose names start with _ are invisible in BigQuery, which meant that users weren't able to view this schema to change their permissions.
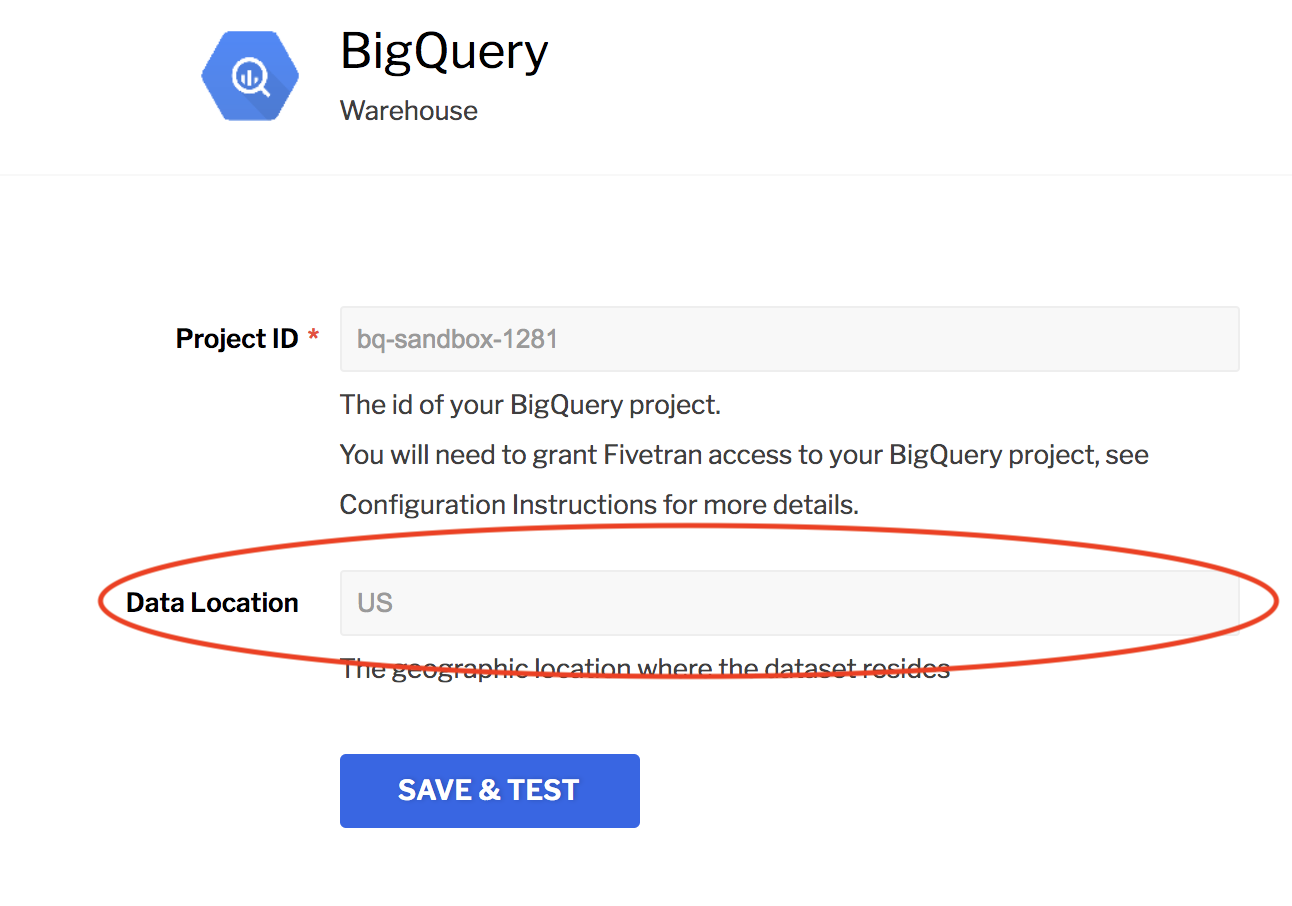
You can now set your preferred dataset location to EU in the BigQuery setup wizard. Once the location is set, Fivetran localizes all datasets we create.
Braintree
We now re-sync all subscriptions once a day to ensure that we capture every change. Previously, we only synced new subscriptions.
Transactions with the status SETTLEMENT_DECLINED no longer cause repeated re-syncs.
Out-of-date SUBSCRIPTION_ADD_ON and SUBSCRIPTION_DISCOUNT rows are now properly deleted when you edit these subscriptions. Previously, it was possible to be left with extra rows when you reduced the number of add-ons or discount lines in a subscription record.
Files
If your file store contains an invalid .zip file, we will skip syncing it and issue a warning.
Google Ads
The CLICK_PERFORMANCE_REPORT table is now limited to fetching 90 days' worth of data, which is AdWords' maximum retention.
Google Cloud Logging
We now use a service account to connect to your Cloud Logging logs. Previously, we used a key file.
Google Play
You can now view the list of your tables that are available for sync in your Fivetran dashboard.
HelpScout
You can now view the list of your tables that are available for sync in your Fivetran dashboard.
HubSpot
We will now re-sync the entire ENGAGEMENTS table when there are more than 10,000 changed records, because HubSpot can no longer complete incremental queries to the engagements endpoint when there are so many changed records.
Some HubSpot records have very old timestamps (for example,Jan 1 1970). These values no longer cause our syncs to fail.
Jira
We now remove the relationship between an issue and an issue label if the issue is removed in Jira.
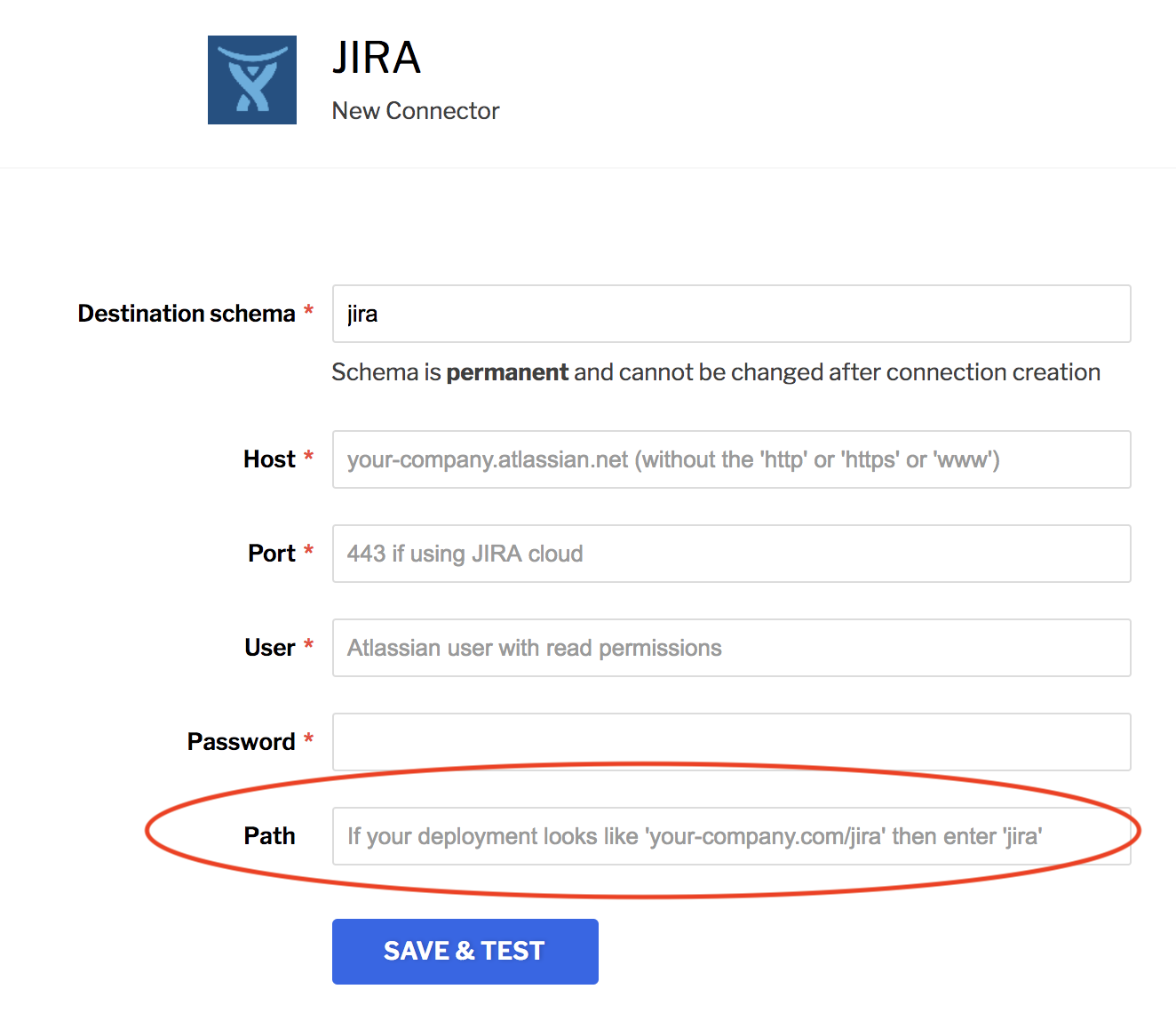
If you deploy your Jira to a custom root path, you can now specify that path in our setup form:
Marin Software
Marin Software occasionally includes irrelevant files in their FTP source. We now only sync files listed in your manifest file, and ignore all others.
MongoDB
During connector setup, we now verify that we have the correct permissions to list all your tables.
MySQL destination
If your destination uses a MySQL version earlier than 5.7, you can't use the timestamp column as a primary key because MySQL incorrectly handles the decimal part of the timestamp. We now detect this scenario, skip tables with this column during our sync, and warn you to upgrade your destination MySQL version. Note that this limitation only applies to MySQL destinations, not MySQL sources.
Oracle
Oracle's DATE data type is really a TIMESTAMP WITH TIME ZONE. It is a common convention to use midnight as a way to represent dates in Oracle. We now detect this pattern and convert these values to DATE in the destination. If you currently have an Oracle connector, you will need to change the existing TIMESTAMP WITH TIME ZONE columns in your destination to DATE columns in order to leverage this feature.
When performing the initial sync of large tables from Oracle RAC sources, we now use smaller block ranges to avoid getting interrupted by multi-node transactions.
We receive changed data from Oracle using LogMiner, and we use the system change number (SCN) as a cursor. We now use smaller ranges of SCNs to reduce the probability of a failed request.
You now get a warning in your Fivetran dashboard when no database transactions have been committed for over an hour after the start of the transaction.
Recharge
The Recharge API sometimes returns non-number values in the price column of the ADDRESS_SHIPPING_LINE table, so this field is now a STRING.
The note_attribute column in the CHARGE_NOTE_ATTRIBUTE table can now contain nested JSON values. For example:
[
{
"name": "How did you hear about us?",
"value": "Social_media_ad:"
},
"some attribute"
]
Redshift
We have changed the way we reclaim disk space from deleted rows. You can find additional details in our Redshift documentation.
Salesforce
We have upgraded our Salesforce connector to Salesforce API version 41.
Segment
We now accept user_id values that are wrapped in an array, for example, "userId":[1].
The iTunes Store API occasionally returns malformed XML due to a lack of string-escaping. We now detect this malformed XML, issue a warning, and skip the bad data during our syncs.
When we encounter a new branch that has no shared commits with the default branch of the repository, we now sync the entire commit history of that branch.